Constructing Computational Models from Historical Texts: A Consideration of Methods
In order to identify periods of millennial expectation in the development of Seventh-day Adventism and show the effects of those periods on the culture of the religious movement, I used the computational method of topic modeling to identify patterns in the language of the denomination over time. I chose this method in consideration of the quality of the available data, the assumptions regarding time embedded in existing algorithms, and the research questions of the dissertation. Foundational to my research and shaping the interpretive possibilities of the project as a whole, there are three methodological aspects that require a more detailed discussion.
- The first is my selection of a corpus for illuminating broad patterns across the denomination.
- The second is my approach to processing that corpus in preparation for computational analysis, and the ways my choices during text preparation shaped the analysis.
- And the third is my selection and use of a topic modeling algorithm that both fit the textual data at hand and helped illuminate overall patterns in the language of the denomination.
Discussion of methods, such as what follows here, and a commitment to reproducible code provide the information necessary to evaluate research based on computational analysis. One persistent critique of arguments based on computational analysis is that it is difficult to assess the soundness of the arguments.1 Even between projects that use similar modes of computational analysis, variations in corpus selection and processing can lead to conclusions that are difficult to compare. Some of that difficulty can be addressed by discussing the methodological aspects of the project, such as the match between sources and question, the applicability of algorithms to the questions at hand, the process of applying the algorithm to the data, and the evaluation of the resulting model. Additionally, executing and documenting code in ways that can be reproduced by others makes visible the implicit and explicit assumptions enacted in the code, opening it to evaluation and critique. By describing my sources, computational approach, and methods of interpretation, I am providing the means by which the project can be verified and assessed, similar to how footnotes and discussions of research methods support the verification and assessment of historical research presented in monograph form.
Developing a Corpus for A Gospel of Health and Salvation
To identify significant and meaningful patterns in the development of the religious culture of Seventh-day Adventism, this project requires an appropriate set of sources to abstract from, both in terms of content and format. As I discuss in the introduction and Chapter 1, periodicals played a key role in the development of the religious culture of early Seventh-day Adventism, and as such provide content well-suited to the intellectual question at hand. While most nineteenth-century religious denominations utilized print to connect their members, as a medium for evangelism, and as a forum for articulating theological differences, periodical literature played a particularly important role in the development of early Seventh-day Adventism.2 It was to periodicals that Ellen and James White first turned in their work to unite the adventists in the years after Miller’s failed prediction of the second coming on October 21, 1844.3 Ellen White defended the use of periodicals in 1850, reporting that she was shown in a vision that God was seeking to bring his people together around the truth of the seventh-day message, an effort that required “that the truth be published in a paper, as preached.”4 The numerous publications of the denomination functioned as the force that brought into being the movement’s “imagined community.”5
While the content of the periodicals provides a window onto the denomination’s developing theology and culture, the denomination has also invested in sharing their teachings as widely as possible through the large scale digitization of their historical materials. This commitment includes the official editing and publication work of the Ellen G. White Estate, which has focused primarily on White’s writings, lay efforts to digitize the denonination’s periodicals, and current work to aggregate the digital resource of the denomination in the Adventist Digital Library.6 As a result of these efforts, a large collection of the historical materials of the denomination are openly available in digital formats, making computational analysis of this material feasible.
The main collection of denominational periodicals is available through the website of the Office of Archives, Statistics, and Research, part of the General Conference of the denomination. This collection privileges the bureaucratic documents of the denomination, including statistical documents, minutes and reports, and the major periodical titles of the denomination. Despite this institutional focus, the collection provides access to a wide variety of periodical literature produced by the denomination, including the central organs of the denomination as well as regional and college publications.
Union conferences included in study
I focused my study on the periodical literature produced from four geographic regions within the United States: the Great Lakes (organized within the denomination as the Lake Union Conference), the West Coast (Pacific Union Conference), the Mid-Atlantic (Columbia Union Conference), and the Southern Mississippi River Valley (Southern Union Conference). These four regions were home to the major publishing and health reform centers of the denomination, and were sites of missionary activity as well as contention over the leadership of the denomination. Focusing on these four regions also provides a useful balance between two of the largest regions of the SDA (Lake Union and Pacific Union) and two of the smaller regions (Columbia Union and Southern Union).
Using the boundaries of the regions as defined by the denomination in 1920, my initial research step was to gather the publications that were produced within these four regions and which have been digitized by the denomination. Because this is a specialized historical collection, only a few of the Seventh-day Adventist periodical titles have been digitized as part of large digitization projects, such as HathiTrust, and a few titles are included in the Historical Periodicals Collection produced by the American Antiquarian Society. The most extensive and easiest to access collection of the periodicals has been produced by the denomination itself.7
Limiting my selection to periodicals published from within the above four regional conferences and digitized by the Seventh-day Adventist denomination, I gathered a corpus composed of thirty different periodical titles, of which there were 13,340 issues and 197,943 pages of material. For a full list of the titles included in this study, see Table 2.2. This scale of materials is important, as it enabled me to pursue a richer understanding of Adventist discourse than I could achieve were I to rely on one or two titles alone. But it also requires approaching the materials differently, relying on computational tools to identify areas of interest and to surface general patterns in the discourse of the denomination, with an awareness of the strengths and limitations of both the data and the methods.
The largest periodicals in my study are the four centrally produced denominational titles — the Review and Herald (RH), the Youth’s Instructor (YI), Signs of the Times (ST), and the Health Reformer (HR). In these titles, the leaders of the denomination sought to guide beliefs and practices, publishing pieces on theology, health, and the everyday life of Seventh-day Adventists. Also through these publications, community members responded back to the leadership through letters and submissions of their own. The corpus contains twice as many pages of the largest title, the Review and Herald, than of the next most significant contributor, the Health Reformer. Together, the Review and Herald, Youth’s Instructor and Signs of the Times, plus the General Conference Bulletin, The Present Truth and Advent Review constitute half of the entire corpus, weighting the dataset heavily toward the centrally produced publications of the denomination.
However, relying on the central publications would provide only a partial picture of the diversity of thought and practice within the denomination. While vital to understanding the development of the institution over time, the viewpoints expressed in these publications privilege the official positions of the denomination. Covering a number of topical and regional focuses, including education, health, missions, and “religious liberty,” the other half of my corpus offers a different range of voices.8 Many of the newly-formed regional and area conferences began producing their own periodicals in the early 20th century as a way to connect the local community, as well as to report back to the international denomination. These regional publications, although often short-lived, provide colloquial information on the activities of the denomination, featured reports from the local conferences, letters, and updates on the activities of the conference, particularly with regards to selling denominational literature.
The proliferation of topical and regional publications also created challenges for denominational leaders, particularly when the viewpoints presented came into conflict with the official position of the denomination. Traces of these conflicts can be seen in the remaining archival record, as the efforts to shape and control the denomination’s message continues into the present. A useful example of this can be seen in the digitization and distribution of the denomination’s health periodicals. The Health Reformer was one of the early publications started by James and Ellen White, and was the first new publication launched after the denomination organized in 1863. By 1875, John Harvey Kellogg had taken the lead as the principal editor and his control over the publication was such that the content of the periodical reflects the development of Kellogg’s own understanding of health as it changed over time. In 1907, Kellogg was disfellowshipped by the denomination, though he retained control over the publication of the Health Reformer and continued its publication well into the 20th century. The archivists and digitization teams at the Seventh-day Adventist church, however, did not include any issues of the Health Reformer (later known as Good Health) after 1907, an archival enactment of denominational politics and reflective of the fact that after 1907, Kellogg was no longer considered to be a voice of the denomination. Rather, Life and Health, which was published out of Washington, D.C., became the central publication for the denomination’s health message, one that was under closer control by the religious leaders of the church than the Health Reformer ever was.
Beginning in 1883, twenty years after they formally organized, the SDA began publishing yearbooks to record and disseminate information about the denomination, including information on who held leadership roles within the different state and regional conferences and the various institutions connected to and run by the denomination. These publications contain a plethora of information about the organization, finance, and leadership of the early church, and useful for my purposes, information about the different publishing ventures undertaken. Using the data in the yearbooks, it is possible to provide a sketch of the publications that are missing from this study.
The budget reports and advertisements published in the yearbook from 1883 indicate that the main periodicals produced by the S.D.A. Publishing Association, then based in Battle Creek, Michigan, were the Review and Herald, Youth’s Instructor, and Good Health (Health Reformer), along with four non-English titles — Advent Tidende (Danish), Advent Harolden (Swedish), Stimme der Wahrheit (German), and De Stem der Waarheid (Dutch). The Pacific Seventh-day Adventist Publishing Association, based in Oakland, California, produced one English-language title, Signs of the Times, and one additional title, Les Signes des Tempes, was produced in French in Switzerland.9 I chose not to include the foreign language titles in my study to focus on the development of the English-language discourses within the denomination. With those excluded, the titles listed in the 1883 yearbook indicate that the titles I have included in my study encompass all of the English-language periodicals produced by the denomination at that point in time and presumably for the first 30 years of its development.
In the years after 1883, the number of publishing houses and topical and regional titles began to increase precipitously. As some of these titles had relatively short publication histories, I examined the yearbooks from 1890, 1904, and 1920 to identify the new reported titles and to compare those to the available digitized titles. Again focusing on only the English-language titles produced from within my four regions of study, I identified twenty relevant titles that had not been digitized by the denomination at the time of my study. These were: The Southern Watchman, Bible Students’ Library, Apples of Gold Library, Our Little Friend, East Michigan Banner, The Haskell Home Appeal, The Illinois Recorder, Southern Illinois Herald, The Wisconsin Reporter, Signs of the Times Magazine, The Present Truth, The Medical Evangelist, and Field Tidings. In addition, of the eight college publications, only the The Sligonian has been digitized by the denomination.10 Although it has also been digitized, I did not locate the Sabbath School Quarterly in time for inclusion in this study. In total, out of the 52 titles produced by the denomination between 1849 and 1920, 29 of the titles, or 55%, were available in digital formats and included in my study. If the college publications are excluded, 28 of the 44 main denominational periodicals, or 63%, were available digitally.11
In addition to these missing titles, there are a number of holes to note in the digitized record as it stood at the time of this study. Whether because the original materials have been lost or due to digitization priorities, the denomination does not have full runs available for all of its digital titles. Most notably, the digital coverage of the Youth’s Instructor is sporadic, especially for the 19th-century, with holes in coverage between 1856-1859; 1863-1870; 1873-1879; 1891-1895; and 1896-1898. This publication, the second denominational title produced by James White, contained material aimed at educating children in the Seventh-day Adventist faith. This is also a title that was frequently written for and edited by the women leaders of the denomination. Additional titles with significant gaps in coverage are The Welcome Visitor (later retitled the Columbia Union Visitor) and The Indiana Reporter. The gaps in digital materials from these publications require creative strategies to use the limited issues available to reveal the distinctive voice these editors provided to the developing community.
I have documented the discontinuities between the sources digitized by the Seventh-day Adventist denomination and the record of their publication history in order to model a critical engagement with a digital collection of materials. By documenting what is included and excluded from the digital collection, I am able to understand the limitations of the data I have at hand and begin to develop strategies for addressing those limitations in my analysis. The documentation also reveals opportunities for the extension of my analysis. While my study is focused on the rhetoric within the U.S. faction of the denomination, the denomination had a significance presence globally, particularly in Australia. For those interested in the religious culture within other regions of the U.S., the regional titles from those areas could be added. An analysis of the non-English titles could be added to explore how the denomination shifted their message when addressing European immigrant groups in the United States. Additional work could be done comparing the health literature of the denomination to that produced by other health reformers of the day.
Preparing Text for Analysis
For scholars working with digital sources, particularly for computational analysis such as text mining and natural language processing, there is much to be gained by attending to the quality of the data and, where possible, improving that quality. The strength of computational algorithms is that they perform consistently and logically upon whatever data they are given. The weakness is that, unlike a human reader who will generally infer that the “IN S TRUCT OR” they encounter in a periodical entitled “Youth’s Instructor” most likely should be read as “INSTRUCTOR,” the computer, unless trained to do so, will make no such inference. The data given to it will be processed literally, in this case as four distinct words. As a result, the quality of the output depends directly on the quality of the initial data. If that data is riddled with errors, then the models created will reflect those errors, and frequently exacerbate them. As the adage goes, “garbage in, garbage out.”12
Because of the significant effect transcription errors can have on the ability to search, classify, and analyze texts, scholars in computer science and information retrieval, as well as across the digital humanities, have developed a number of strategies for identifying and correcting regularly occurring errors. Much of this work has focused on texts produced before the 19th-century, as the difference in typographical conventions, such as the long s (ſ), create known challenges for modern OCR engines. In addition to developing a series of regular corrections to received textual data, current work in information retrieval is focused on using probability and machine learning to estimate the most likely correct substitution for errors using general language patterns.13 The work of computationally correcting the errors generated during character recognition is an important step in developing a source base that is reliable for tasks from information retrieval to computational analysis, and is particularly important when working with the peculiarities of historical documents.
Optical Character Recognition and the Creation of Digital Texts
Institutional investment in the creation of digitized historical documents has reached the point where there is a sufficient amount of materials available to begin to engage questions of how digital and digitized resources might be used in computational historical studies. In addition to the resources of Google Books, HathiTrust, the Internet Archive, and Project Gutenberg, historians looking at the United States have the collections of the Library of Congress, the National Archives, and the Digital Public Library of America, along with a multitude of state, local, and organization-level digitization efforts, as sources for digital content. When vendor controlled resources, such as those from Gale, ProQuest, and Ancestry.com, are added to the list, there seems to be an overwhelming abundance of digital materials available for historians to work with.
It is tempting to look at this scale of digital material and to conclude that “Historians, in fact, may be facing a fundamental paradigm shift from a culture of scarcity to a culture of abundance,” though shifting political realities raise concerns regarding the fragility of the digital record.14 The digital record presents a wide range of challenges for current archival and research practices. On the one hand, questions of the stability of digital objects and the media upon which they depend requires engagement with the technical work of migration, emulation, and digital forensics as part of archival practice to mitigate the problems of bit rot and technological obsolescence that threatens digital records. At the same time, an abundance of digital materials does not necessarily equate to the quality of those materials or their usefulness for computational analysis. The apparent abundance of the current digital record elides numerous problems with the scope and quality of the materials that have already been translated into digital media.
This is due to the processes by which the physical materials of the past are translated into their digital counterparts. The first stage of digitization of a material object is imaging — the creation of a digital facsimile of the object through the use of some sort of imaging technology, most often through the use of a digital camera or a scanner. While the best facsimiles are created using the original printed materials, often digitizing agencies use previously created microfilm and microfiche materials as the source for digital objects as a cost and time saving measure. These digital files are displayed online or distributed on various media such as CDs or flash-drives, and, assuming the image quality is at least mediocre and the original document was in good physical condition, can be deciphered by human readers.
However, the computer only recognizes these files as image files — collections of pixel information with no text information. This brings us to the second phase of digitization: transcription. The creation of a text layer for images of textual materials can be done in a variety of ways. Manual transcription involves the work of a human actor who reads the original document and creates a corresponding digital document. This work is slow, though at times when the original document was handwritten or has physical features that make the text difficult to read, it may be the only currently viable way to create a digital text. In most cases, however, researchers rely on Optical Character Recognition (OCR) to decipher text from image files. OCR uses various algorithms to match patterns in an image file to the most likely corresponding letter, and the error rate for a recognition task reflects the percentage of characters that are correctly identified. The advantage of OCR is that it can be used to process a large number of image files quickly and, on the whole, accurately, enabling computational access to written words that were previously only interpretable by a human reader.
While at the core of modern efforts to bring the past online, the challenges of working with text generated through OCR compound as one moves backward through time, as the documents become further removed from the modern materials used to develop and train the software and the standardization of everything from font and layout to spelling decreases. Because OCR engines were created for (and trained on) printed text from second half of the 20th century, the error rates for materials published earlier tend to be higher. Differences in typography, in layout conventions, and lack of standardized spelling all contribute to the errors that OCR engines are likely to make when processing historic documents. In addition, physical blemishes, such as tears, stains, and discoloration in the case of the material objects, low image quality, and previous scanning errors introduce additional challenges for the OCR engine. It is this textual layer, particularly when it is created using OCR software, its use in digital corpora, and its limitations and their potential remediation that both enables and constrains the use of computational methods with historic documents.
Within historical scholarship, the limitations of the current digital materials are often first encountered within the context of search and retrieval, as these are modes of interaction that define the majority of scholars’ interactions with the digital and digitized ecosystem. While the promise of the online database is that millions of texts are merely a keyword search away, how well that promise is being fulfilled is not easy to ascertain. Studies of the material included in the Eighteenth Century Collections Online (ECCO) collection and within the Burney Collection, which is a Gale product containing 17th and 18th century English newspapers, raise significant concerns about the representativeness of the documents included in these prominent subscription databases and the quality of the available data.15 For historians working from digital materials, regardless of method, tackling questions of data transparency and accuracy is of increasing importance as part of documenting the process of historical research.
These data challenges are not limited to large subscription sources, as documented by the Mapping Texts project from the University of North Texas and the Bill Lane Center for the American West at Stanford University, and supported by the National Endowment for the Humanities. Originally conceived with the goal of developing tools and strategies for identifying meaningful patterns within the millions of newspaper pages of the Chronicling America project, the teams quickly realized that their ability to ask research questions of the data was dependent upon understanding which questions “could be answered with the available digital datasets …”16 To address this problem, the Mapping Texts team created an interface that highlights the coverage of the newspaper collection, particularly in terms of geography and dates, as well as the quality of the data.
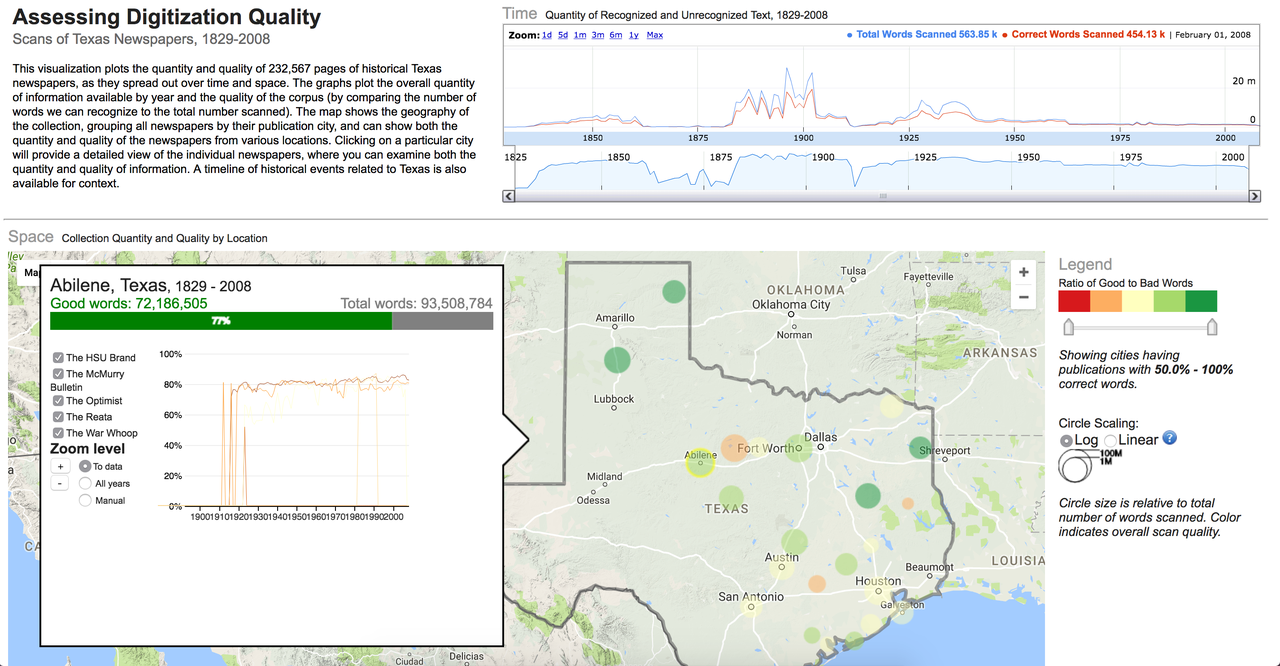
The resulting interface shows an overall low “good word” rate across the Texas newspapers in Chronicling America, with most of the best performing areas hovering around 80% while worse performing areas hover around 60% of the identified words being recognized.17 This data enables readers to temper their expectations about what can be known from the analyzed data, a useful counterbalance to the seeming expansiveness and authority of digital materials.
The situation encountered by the Mapping Texts team is not unique to the Chronicling America data. A quick browse through the “text view” of content in HathiTrust and Google Books reveals that it does not take very many OCR errors to make the text illegible. In the case of vendor resources, it is harder to ascertain the quality of the data, as noted previously, because they tightly control their content through contracts with research libraries. However, unless the vendors have devoted massive resources to the correction of their textual data, it is safe to assume that their data suffers similar error rates. This is also true for other third-party data sources, such as the online archives of the Seventh-day Adventist church.
In preparing my corpus for analysis, I considered two of the challenges that historical documents raise for OCR and automated text extraction: errors in character identification and errors in layout recognition. Of these, I found that character recognition errors are the primary error discussed in the computer science and information retrieval literature, as these can be addressed after the fact more easily than errors in layout recognition and are more detrimental for standard search functions. However, errors in layout recognition pose potential challenges for algorithms that represent relationships between words, a representation that is infrequently used in current databases, but which is increasingly prominent in computational text analysis.
Character Recognition
Errors in character recognition are perhaps the most common, and best known, problem encountered when moving from a physical to a digital object. From decorative borders that are interpreted as strings of “i”s and “j”s to confusion between characters such as “e”, “c”, and “o”, these are the errors readers first notice when glancing at the “text view” of digitized documents. Recognition errors create problems across a wide range of processing functions, including search and retrieval and natural language processing tasks, and as a result there is a significant field of literature from both computer science and digital humanities describing strategies for improving the quality of text generated through OCR.18 Some of these errors, such as mis-recognized line endings, out of place special characters, and the like, are possible to address with various forms of search and replace. Errors within words, however, are a more difficult problem to address. Because of the complexities of the word errors, simplistic strategies, such as creating lists of error-correction pairs or using standard spelling programs, have been shown not only to fail to improve OCR quality in historical documents, but to result in higher recorded error rates.19 By and large, the scholarship in the field indicates that approaches that combine information about word-use probabilities and the surrounding context are most successful at replacing errors with the correct substitution.
There are two basic approaches for evaluating the accuracy of transcribed data: comparison of the generated text to some “ground truth” or text that is known to be accurate and comparison of the words in the generated text to some bank of known words. The first method is used by Simon Tanner, Trevor Muñoz, and Pich Hemy Ros in their evaluation of the OCR quality of the British Library’s 19th-Century Online Newspaper Archive. Using a sample of 1% of the 2 million pages digitized by the British Library, the team sought to calculate the highest areas of OCR accuracy achieved by comparing the generated XML text to a sample that had been “double re-keyed.”20 While providing very accurate results about the quality of the generated texts, this approach is highly labor intensive. For my much smaller corpus of 197,000 documents, creating a ground truth dataset of 1% represents nearly 1,000 hours of work, assuming that each document could be transcribed with 100% accuracy in 30 minutes. The second approach, and the one pursued by the Mapping Texts team, is to compare the resulting text to some authoritative wordlist. This approach is easier to implement, as it takes much less time to compile a relevant wordlist than to rekey nearly 2000 pages of text. However, the results are much less accurate as the method is blind to places where the OCR engine produced a word that, while in the wordlist, does not match the text on the page or where spelling variations that occur on the page are flagged as OCR errors because they are not included in the wordlist.
Weighing the disadvantages of both approaches, I chose to use the second method, comparing the generated OCR to an authoritative wordlist. The creation of a source specific wordlist also opens up possibilities for error correction using a probabilistic approach, such as that used by Lasko and Underwood.21 However, creating a wordlist that is both sufficiently broad to recognize the more obscure words of the literature but not so broad to miss a large percentage of errors is a challenge.
To solve this, I took an iterative approach, first creating a base wordlist, and slowly adding the more specialized vocabulary used frequently in the denominational periodicals. I chose to use Spell Checker Oriented Word Lists (SCOWL) to generate the base wordlist, rather than the more commonly used NLTK (Natural Language ToolKit) wordlist. This provided me the option to pull from multiple dictionary sources and set various parameters for alternate spellings and range of words.22 To this list, I added words from the King James Bible (sourced from the Christian Classics Ethereal Library), people and place names from the denominational yearbooks, and place names from the National Historical Geographic Information System.
With these wordlists in place, I logged the reported errors for each title and then worked title by title to identify the most frequently reported errors in order to improve the coverage for community specific language. There were two advantages to this step. First, it helped me identify regular error patterns generated by the OCR process, such as extra characters and detached word endings. While the overall quality of the OCR was surprisingly good, the smallness of the font coupled with the tightness of the columns, particularly for the mid-19th century issues, caused the most confusion for character recognition. In addition, the density of the earlier pages seems to have created a challenge for the original publishers in terms of letter availability. A striking number of reported “errors” were due, not to character mis-recognition, but to the intentional use of incorrect characters in the original type — “c” in place of “e”s, for example, or regular ‘misspellings’ of particular words — errors that the human reader easily “corrects” for but that the machine readers does not (nor would we necessarily want it to). These regular errors, which are due not to OCR transcription failures but due to the historical realities of a limited supply of letters and editorial license with spelling, raise questions of normalization when working with historical materials.
Second, it enabled me to identify useful additions to my set of wordlists, additions that also shifted my conception of the type of writing these early Seventh-day Adventists produced. Particularly in the area of health, the Seventh-day Adventist writers used a specialized, and at times, inventive vocabulary for describing ailments and their cures. Their vocabulary, however, was not created from within a vacuum. While the scholarship on 19th-century popular religion tends to emphasize the populism and enthusiasm of revival preachers and adherents, that enthusiasm was also in conversation with literature on theology, educational theory, and medicine.23 The “errors” identified using the default wordlists reveal references to various educational theorists, a wide variety of theologians, and different medical theories and their proponents. Working systematically through the thirty titles of this study, I created a Seventh-day Adventist vocabulary as the wordlist against which to compare the OCR tokens.
Layout Recognition
The second challenge for creating textual data from scans of 19th-century newspapers is the problem of layout recognition when the documents do not match the layout and design patterns of 20th-century (and electronically produced) documents. With space at a premium, publishers packed each page with multiple columns of type in compact fonts. This strategy, while more or less readable to the original human audience, has resulted in images that strain the layout recognition algorithms of OCR software. With thin column lines and narrow, if existent, margins between the text, the recognition algorithm makes reasonable assumptions about the blocks of text, but with the result that the columns are blurred and the text jumbled.24 While this textual soup still provides the necessary data for problems of search and retrieval, the unreliability of sentence and paragraph structures makes standard natural language processing techniques, such as part-of-speech tagging and named-entity recognition, difficult with scanned historical documents. Additionally, the impact of the irregular word order on newer algorithms for textual analysis, such as word-embeddings and deep learning, remains an open question.
For the documents scanned and OCRed by the Seventh-day Adventist church, such problems of layout recognition are a recurring feature within the textual data. To highlight the challenge that layout recognition causes for the OCR of historic newspapers, I used Adobe Acrobat Pro to reanalyze one of the early Review and Herald PDF files, which identified and highlighted the different sections of text that the program recognizes on the page (see Figures 2.4 and 2.5). While sometimes successful, often times the peculiarities of nineteenth-century documents, including the narrow columns and the small font sizes, stretch the recognition algorithms well beyond their capacity.
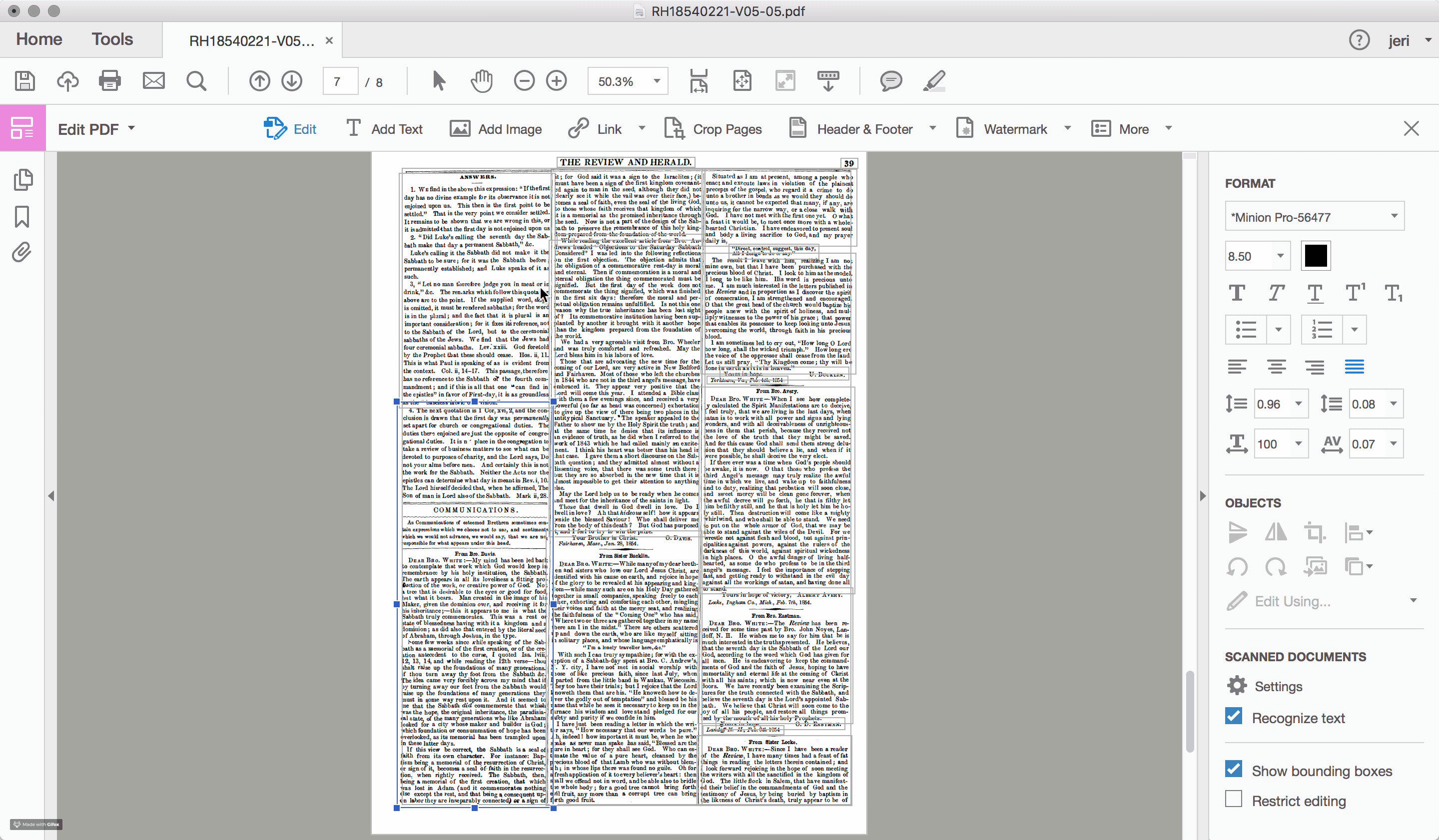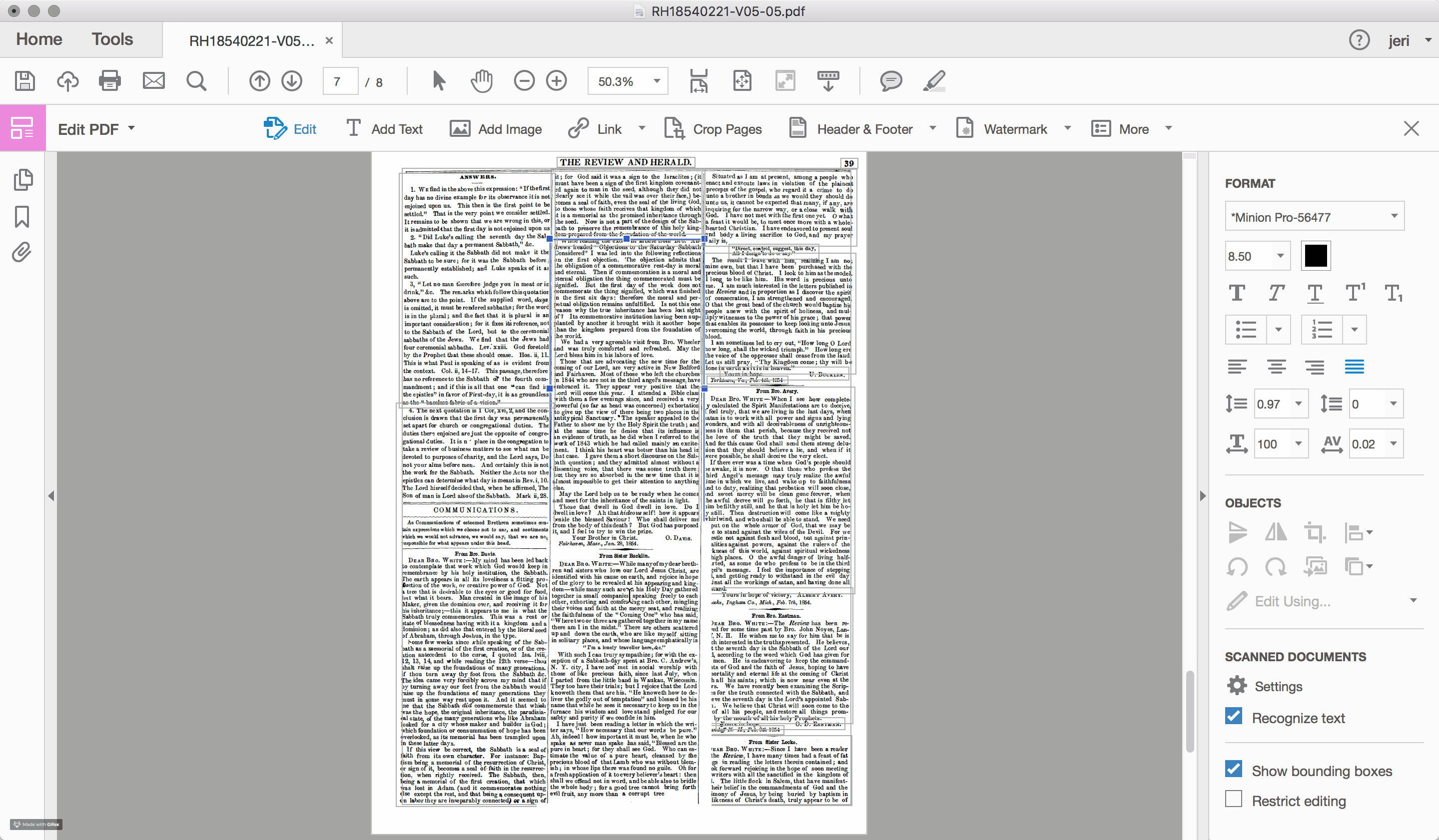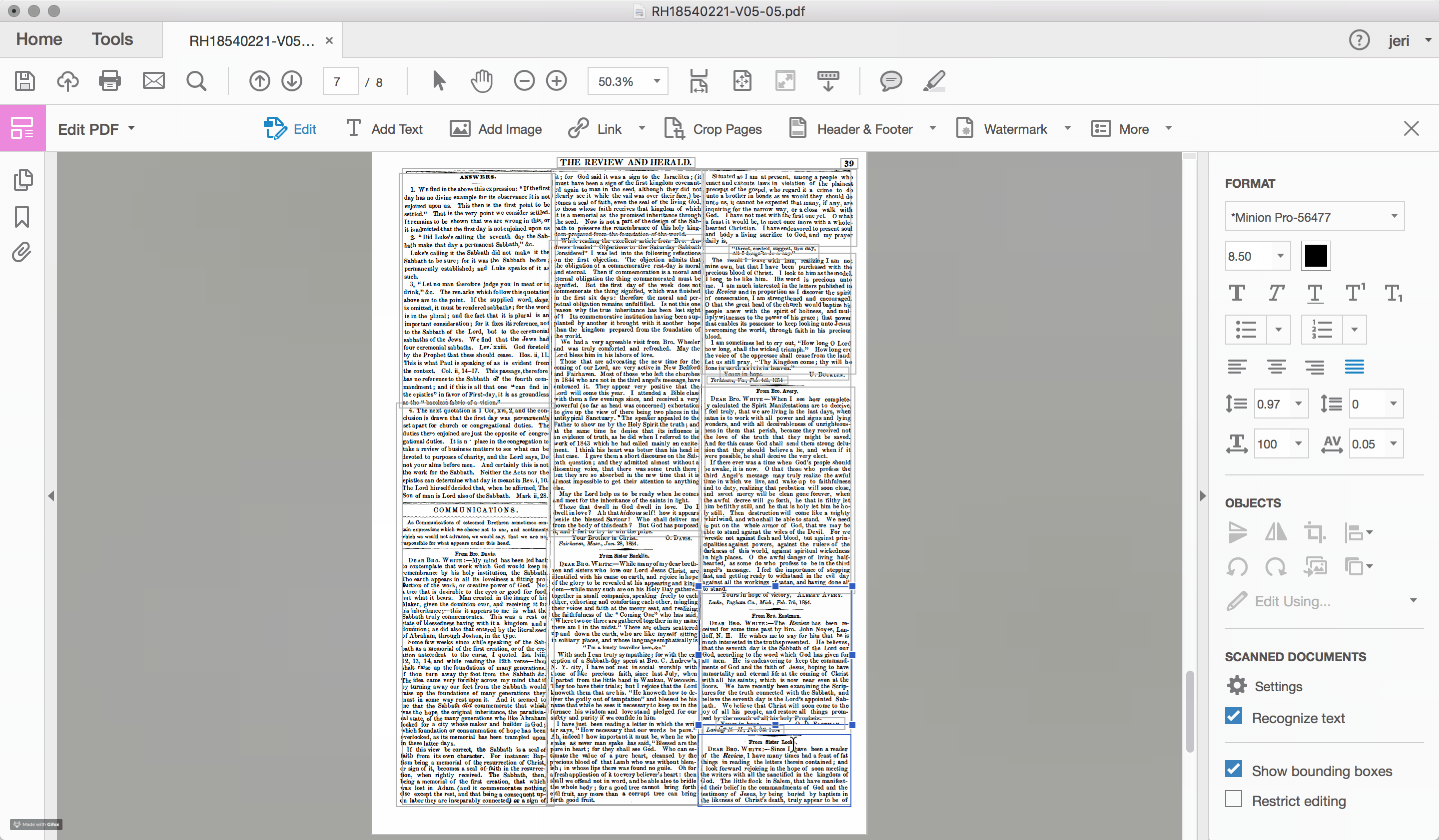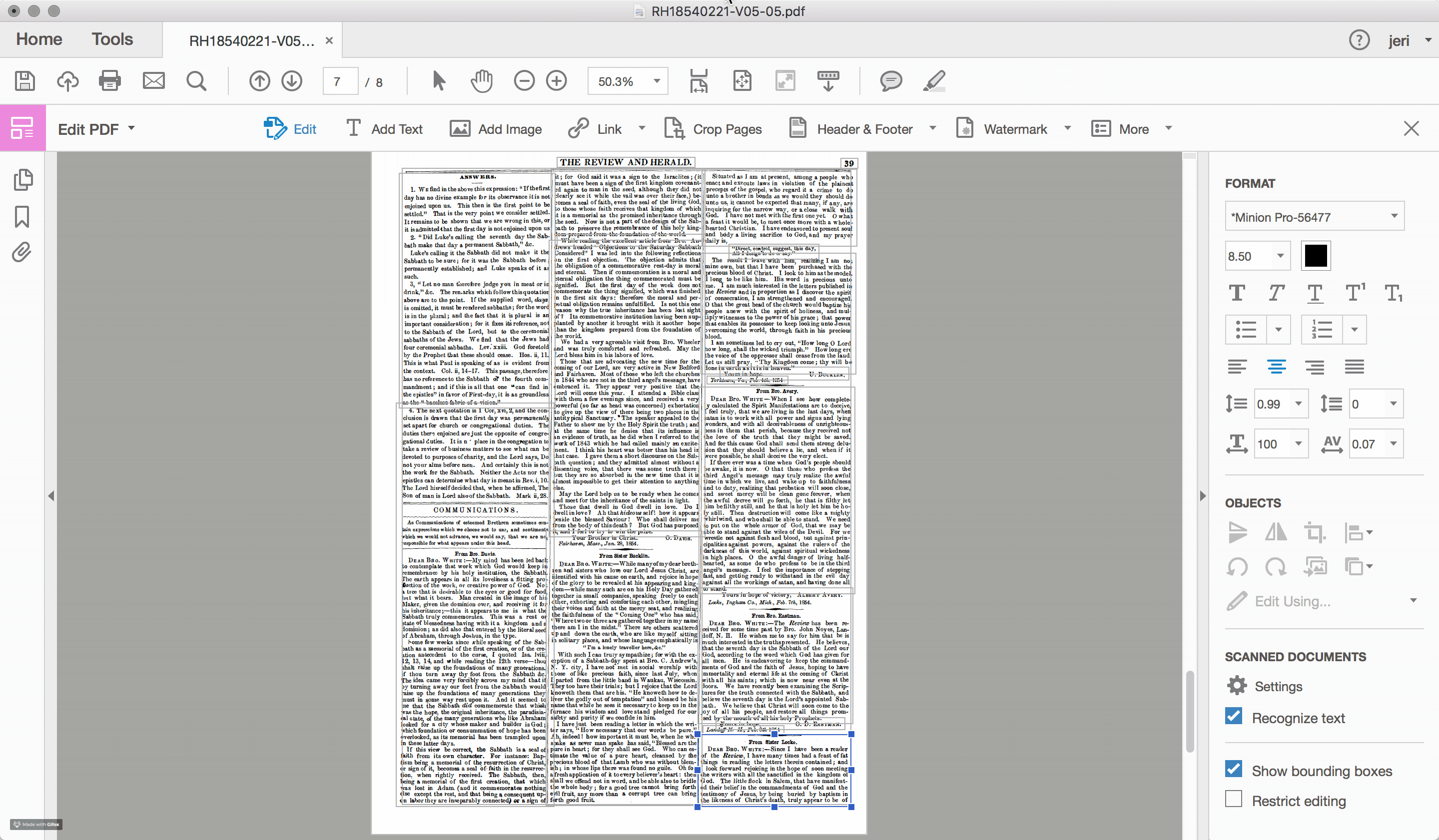
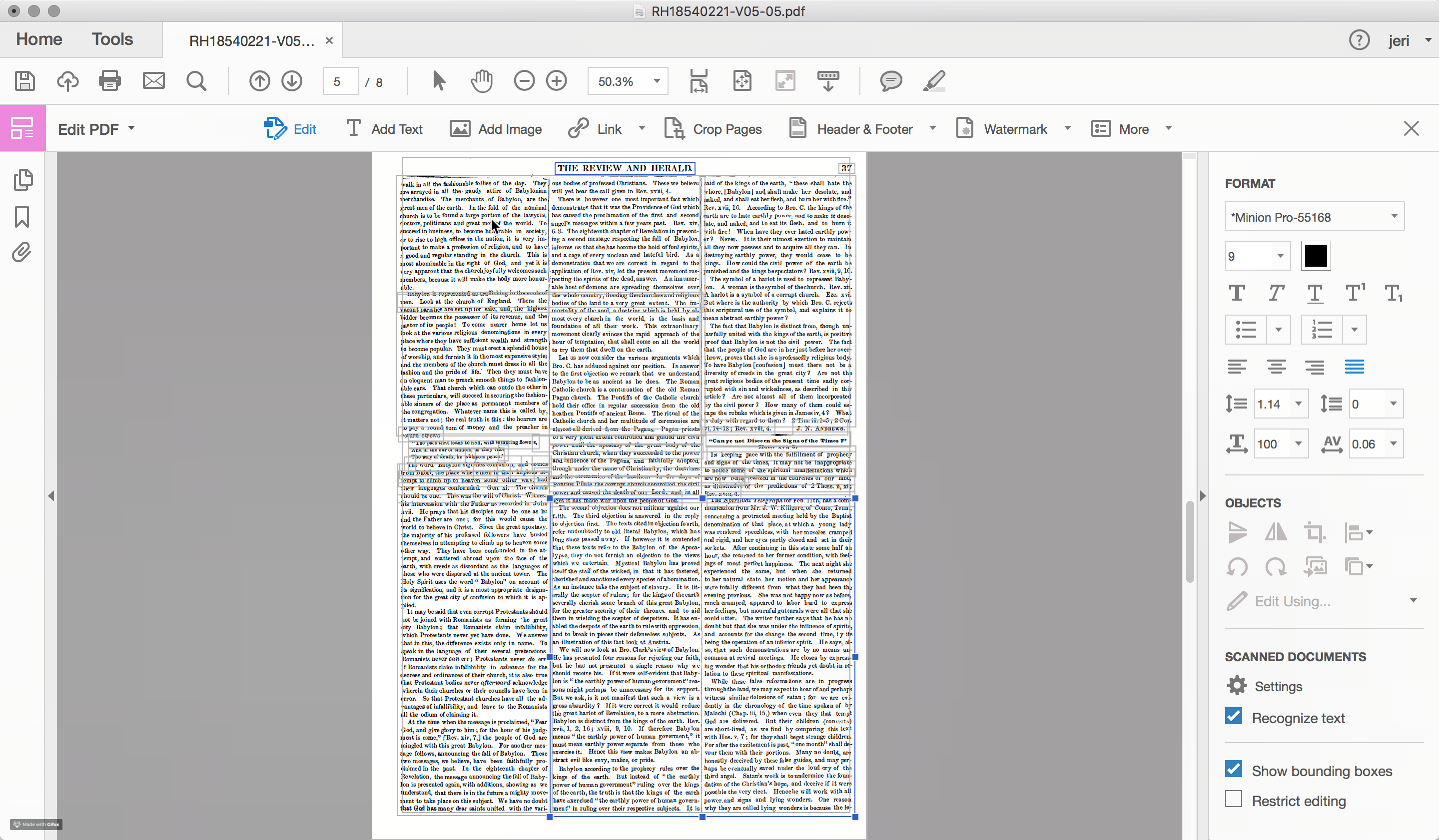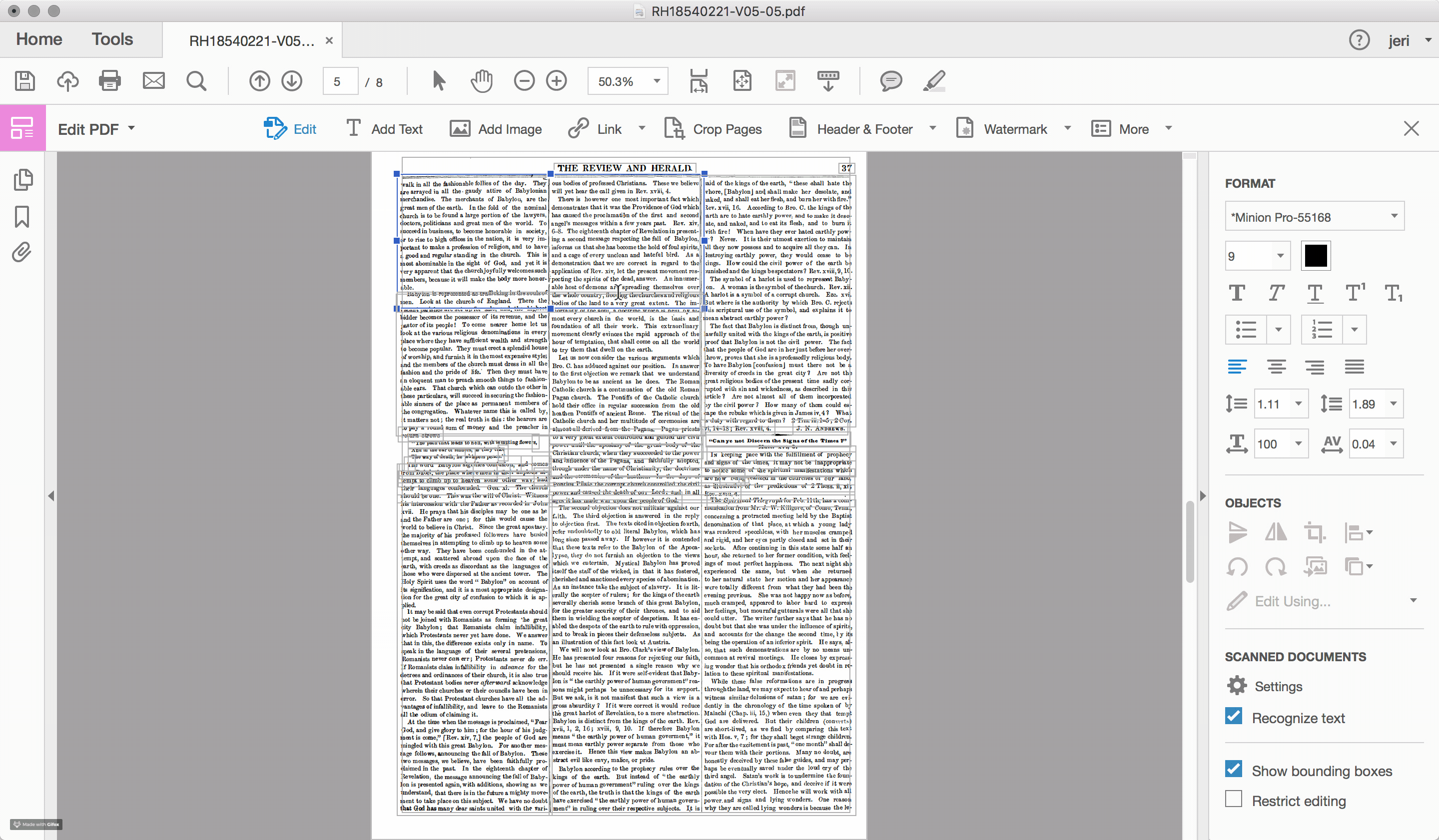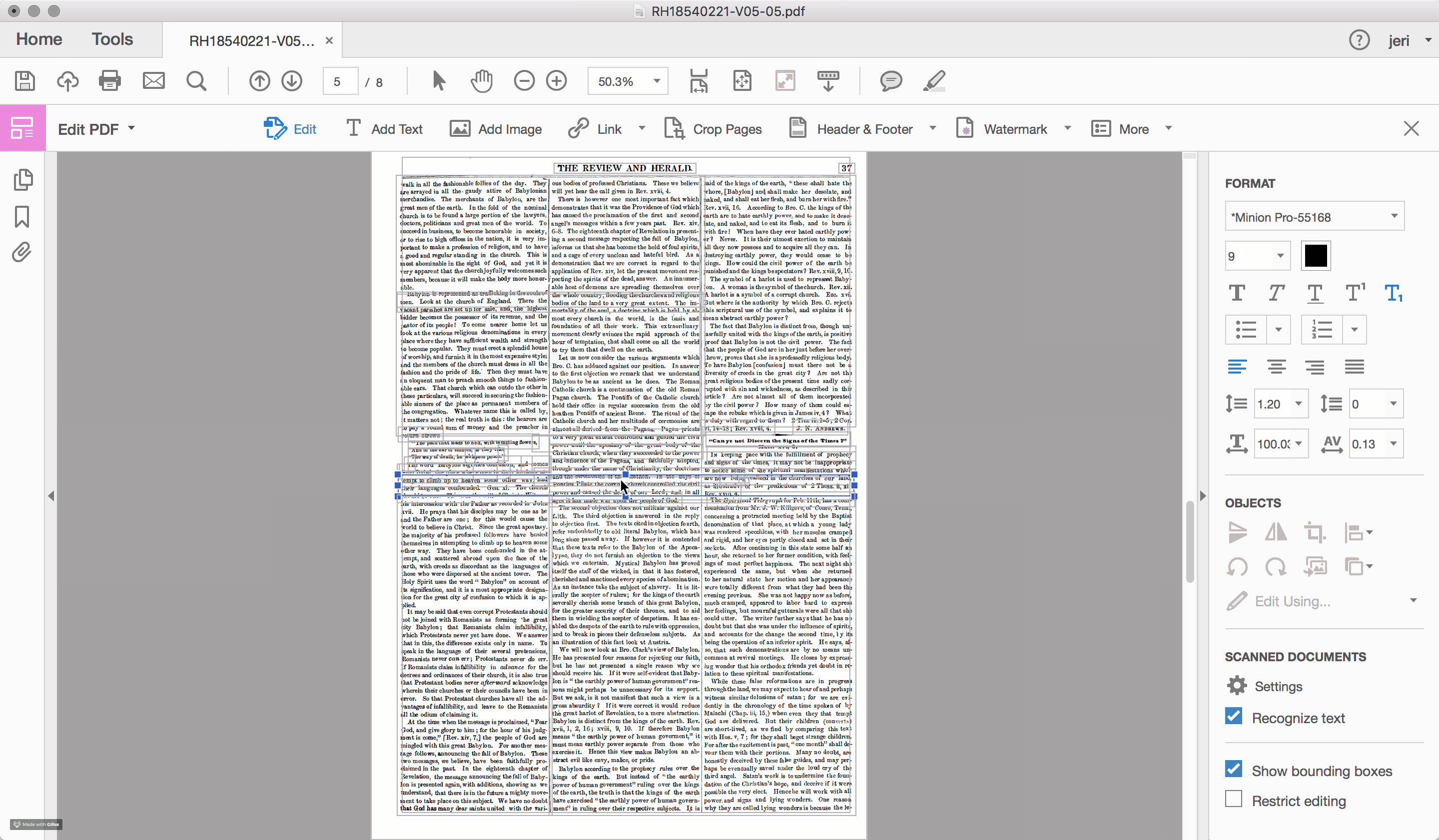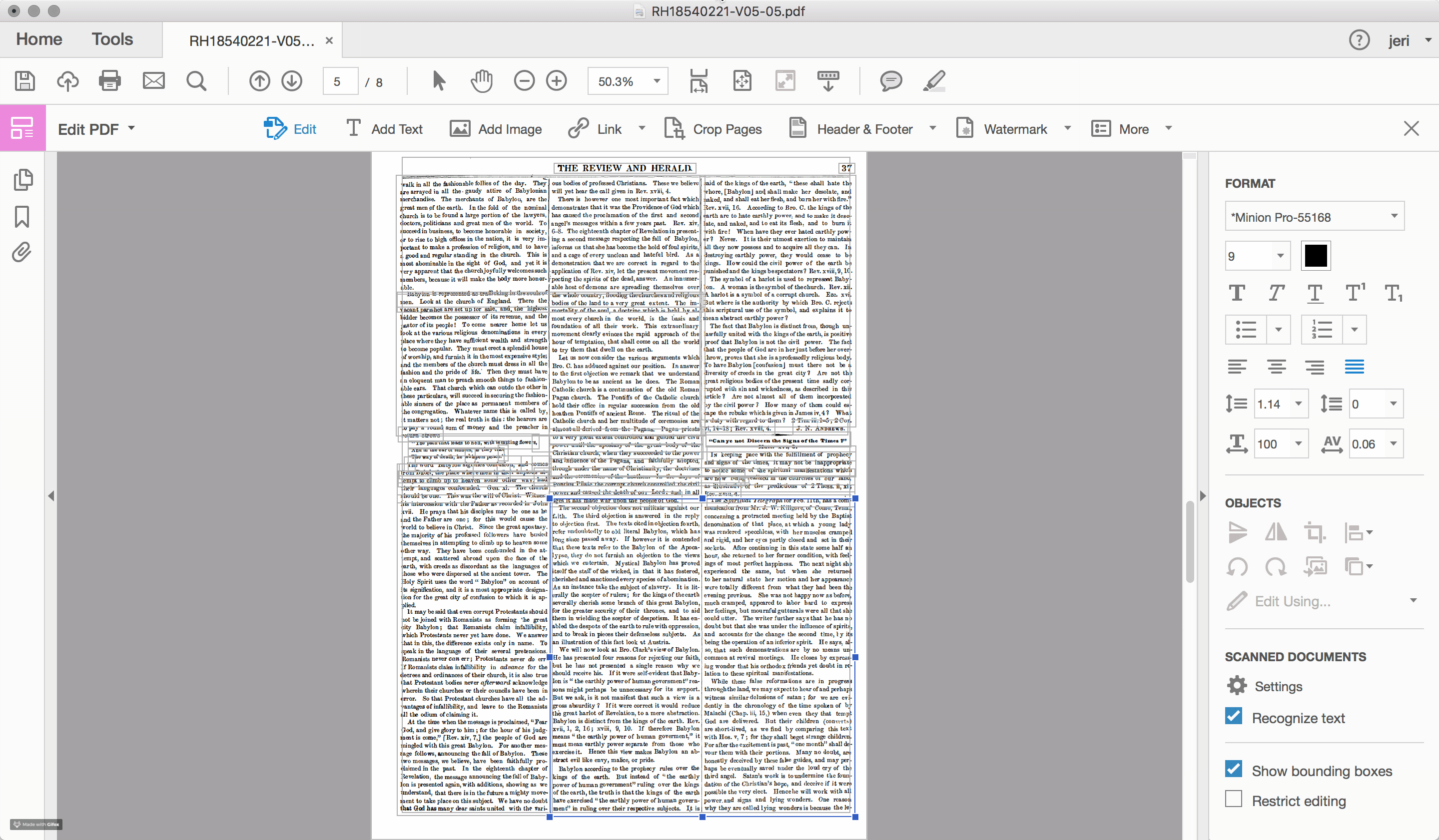
Errors in layout recognition are harder to correct than mistakes in character recognition, in that they are best addressed during the recognition stage of the document processing and, as such, require time. Databases that organize content based on the article (rather than the issue), such as those produced by the American Antiquarian Society, are incentivized to ensure that the boundaries of each article are correctly detected. However, for large scale digitization projects, particularly those with limited budgets, often few resources are devoted to training the OCR engine. For many of these projects, such as the digital archive of the SDA, the primary “reader” of the document is assumed to be human and the primary object is the image file of the original document. The text layer is a secondary feature, useful primarily for search and retrieval.
OCR Correction in Action
What does this look like in practice? To highlight the problems that frequently appear in OCRed documents and the improvements that I made with relatively simple cleaning mechanisms, here is an example of the text from the first volume and issue of The Health Reformer.
The Health Reformer, Vol. 1, no. 1, (August 1866), page 3.
DUTY TO KNOW OURSELVES.
preserve it in a healthy condition. The in their physical organism, will not be present generation have trusted their bod less slow to violate the law of God ies with the doctors, and their souls with spoken from Sinai. Those who will not, the ministers. Do they not pay the min after the light has come to them, eat and ister well for studying the Bible for them, drink from principle, instead of being that they need not be to the trouble ? and controlled by appetite, will not be tena is it not his business to tell them what cious in regard to being governed by they must believe, and to settle all doubt principle in other things. The agitation ful questions o f theology without special
investigation on their part? If they are
sick, they send for the doctorÑbelieve
whatever he may tell, and swallow any a Ò god of their bellies.Ó
thing he may prescribe ; for do they not Parents should arouse, and in the fear pay him a liberal fee, and is it not his of God inquire, what is truth ? A tre business to understand their physical ail mendous responsibility rests upon them. ments, and what to prescribe to make
them well, without their being troubled
with the matter ?
Children are sent to school to be taught
the sciences; butthe science of human life
is wholly neglected. That which is of the
most vital importance, a true knowledge
of themselves, without which all other
science can be of but little advantage, is
not brought to their notice. A cruel
and wicked ignorance is tolerated in re laws that govern physical life. She gard to this important question. So should teach her children that the indul closely is health related to our happiness, gence of animal appetites, produces a that we cannot have the latter without
the former. A practical knowledge of
the science of human life, is necessary in
order to glorify God in our bodies. It is
therefore o f the highest importance, that
among the studies selected for childhood,
Physiology should occupy the first place. be to their children, both teacher and How few know anything about the struc physician. They should understand na ture and functions o f their own bodies, tureÕ s wants ancl natureÕ s laws. A care and of NatureÕs laws. Many are drifting ful conformity to the laws God has im about without knowledge, like a ship planted in our being, will insure health, at sea without compass or anchor; and and there will not be a breaking down what is more, they are not interested to o f the constitution, which will tempt the learn how to keep their bodies in a healthy afflicted to call for a physician to patch condition, and prevent disease. .them up again.
The indulgence of animal appetites has > Many seem to think they have a right degraded and enslaved many. Self-deni to treat their own bodies as they please; al, and a restraint upon the animal appe but they forget that their bodies are not tites, is necessary to elevate and establish their own. Their Creator who formed an improved condition of health and mor them, has claims upon them that they als, and purify corrupted society. Every cannot rightly throw off. Every need violation of principle in eating and drink
ing, blunts the perceptive faculties, mak ing it impossible for them to appreciate or place the right value upon eternal things. It is of the greatest importance that mankind should not be ignorant in regard to the consequences of excess. Temperance in all things is necessary to health, and the development and growth of a good Christian character.
Those who transgress the laws of God
less transgression of the laws which God has established in our being, is virtually a violation of the law of God, and is as great a sin in the sight of Heaven as to break the ten commandments. Igno rance upon this important subject, is sin ; the light is now beaming upon us, and we are without excuse if we do not cherish the light, and become intelligent in regard to these things, which it is our highest earthly interest to understand.
o f the subject o f reform in eating and drinking, will develop character, and will unerringly bring to light those who make
They should be practical physiologists, that they may know what are and what are not, correct physical habits, and be enabled thereby to instruct their children. The great mass are as ignorant and indif ferent in regard to the physical and mor al education o f their children as the ani mal creation. And yet they dare assume the responsibilities of parents. Every mother should acquaint herself with the
|morbid action in the system, and weakens their moral sensibilities. Parents should seek for light and truth, as for hid treas ures. To parents is committed the sa cred charge of forming the characters of their children in childhood. They shouldTo verify that the content generally matches the original document, let’s compare this text to the PDF scan of the original document.25
In comparing the two representations of the text, we can see that, although the individual words seem to have been captured fairly well, the OCR engine was inconsistent in recognizing the column layout of the page.
Evaluating the text against the dictionary I constructed, I generated the following error report:
'>',
'al',
'als',
'ancl',
'ani',
'appe',
'butthe',
'cious',
'doctorñbelieve',
'f',
'ferent',
'ful',
'gence',
'ies',
'igno',
'indif',
'indul',
'ister',
'mak',
'mal',
'mendous',
'ments',
'mor',
'na',
'natureõ',
'natureõs',
're',
'sa',
'self-deni',
'struc',
'tena',
'tites',
'tre',
'ture',
'tureõ',
'ures',
'|morbid',
'ò',
'ó'As initially produced, the transcription of this page reveals a number of the typical errors that I found in the digitized SDA corpus, including problems recognizing punctuation, such as apostrophes, the addition of special characters, such as “ñ,” where the character does not appear in the text, words split into two tokens, and lines spanning two columns of content. To address these, I worked through a series of steps, including correcting the apostrophes, standardizing and removing special characters, fixing words broken due to line endings, and rejoining split words.26 At the end of the process, the transcribed text and the reported errors are as follows:
DUTY TO KNOW OURSELVES.
preserve it in a healthy condition. The in their physical organism, will not be present generation have trusted their bod less slow to violate the law of God ies with the doctors, and their souls with spoken from Sinai. Those who will not, the ministers. Do they not pay the min after the light has come to them, eat and ister well for studying the Bible for them, drink from principle, instead of being that they need not be to the trouble ? and controlled by appetite, will not be tena is it not his business to tell them what cious in regard to being governed by they must believe, and to settle all doubt principle in other things. The agitation ful questions o f theology without special
investigation on their part? If they are
sick, they send for the doctor believe
whatever he may tell, and swallow any a god of their bellies.
thing he may prescribe ; for do they not Parents should arouse, and in the fear pay him a liberal fee, and is it not his of God inquire, what is truth ? A tre business to understand their physical ail mendous responsibility rests upon them. ments, and what to prescribe to make
them well, without their being troubled
with the matter ?
Children are sent to school to be taught
the sciences; butthe science of human life
is wholly neglected. That which is of the
most vital importance, a true knowledge
of themselves, without which all other
science can be of but little advantage, is
not brought to their notice. A cruel
and wicked ignorance is tolerated in re laws that govern physical life. She gard to this important question. So should teach her children that the indul closely is health related to our happiness, gence of animal appetites, produces a that we cannot have the latter without
the former. A practical knowledge of
the science of human life, is necessary in
order to glorify God in our bodies. It is
therefore o f the highest importance, that
among the studies selected for childhood,
Physiology should occupy the first place. be to their children, both teacher and How few know anything about the struc physician. They should understand nature and functions o f their own bodies, ture s wants ancl nature s laws. A care and of Nature s laws. Many are drifting ful conformity to the laws God has im about without knowledge, like a ship planted in our being, will insure health, at sea without compass or anchor; and and there will not be a breaking down what is more, they are not interested to o f the constitution, which will tempt the learn how to keep their bodies in a healthy afflicted to call for a physician to patch condition, and prevent disease. .them up again.
The indulgence of animal appetites has Many seem to think they have a right degraded and enslaved many. Self-deni to treat their own bodies as they please; al, and a restraint upon the animal appe but they forget that their bodies are not tites, is necessary to elevate and establish their own. Their Creator who formed an improved condition of health and mor them, has claims upon them that they als, and purify corrupted society. Every cannot rightly throw off. Every need violation of principle in eating and drink
ing, blunts the perceptive faculties, making it impossible for them to appreciate or place the right value upon eternal things. It is of the greatest importance that mankind should not be ignorant in regard to the consequences of excess. Temperance in all things is necessary to health, and the development and growth of a good Christian character.
Those who transgress the laws of God
less transgression of the laws which God has established in our being, is virtually a violation of the law of God, and is as great a sin in the sight of Heaven as to break the ten commandments. Ignorance upon this important subject, is sin ; the light is now beaming upon us, and we are without excuse if we do not cherish the light, and become intelligent in regard to these things, which it is our highest earthly interest to understand.
o f the subject o f reform in eating and drinking, will develop character, and will unerringly bring to light those who make
They should be practical physiologists, that they may know what are and what are not, correct physical habits, and be enabled thereby to instruct their children. The great mass are as ignorant and indifferent in regard to the physical and moral education o f their children as the animal creation. And yet they dare assume the responsibilities of parents. Every mother should acquaint herself with the
morbid action in the system, and weakens their moral sensibilities. Parents should seek for light and truth, as for hid treas ures. To parents is committed the sacred charge of forming the characters of their children in childhood. They should'al',
'als',
'ancl',
'appe',
'butthe',
'cious',
'f',
'ful',
'gence',
'ies',
'indul',
'ister',
'mendous',
'ments',
'mor',
're',
'self-deni',
'struc',
'tena',
'tites',
'tre',
'ture',
'ures'Through this process, I significantly improved the text, but the errors that remain highlight the challenges of working with text when columns have been incorrectly identified. Because the columns were merged into lines during character recognition, it is difficult to address one of the most common errors, words that have been split due to line endings. While it might be possible to use the average line length to identify and remedy some of the errors, it is difficult to do at scale due to the multiple variations in layout across years and periodical titles.
In working through my corpus for A Gospel of Health and Salvation, I processed each title separately in order to account for the peculiarities of each title, including layout, language, and typography. This approach enabled me to clean the text more carefully than I would have with a batch approach. Working iteratively through the titles, both to generate a list of vocabulary words distinctive to the denomination and to clean the text, informed my understanding of the strengths and weaknesses of the textual data.
Historical Documents, OCR, and Computational Text Analysis
Current developments in computational textual analysis represent words in relation to their surrounding words and their grammatical functions.27 This form of representation is powerful, resulting in significant improvements in computer translation and enabling researchers to explore the relationships between words in new ways.28 The cutting edge of computational text analysis is to be found in analysis that considers language as networked, contextual, and relational.
However, it is unclear whether the textual data I have from the denomination’s digitization efforts can support this sort of analysis. Research is needed to consider the effects of poorly recognized document layouts on the performance of these more complex algorithms, but given that the first rule of analysis is “Garbage in, garbage out,” I am skeptical that I would achieve reliable results from data such as that which I extracted from the periodicals of the SDA. Not that the data cannot be used, but the types of analysis that the data can support are constrained by its quality. Should this prove to indeed be the case, scholarly attention will need to turn again to the digitization of historical documents, prioritizing the textual layer for algorithmic processing.
Careful analysis of the data quality from scanned historical sources is still rare among digital humanities projects, with the notable exception being studies into OCR quality for the purpose of improving information retrieval for large scale digitized collections. This absence is both curious and not unexpected. On the one hand, the quality of the data is critically linked to the potential success of experiments using machine learning algorithms with historical data, a connection that it seems should weigh heavily on researchers’ minds. However, the work involved in diagnosing and addressing errors in character recognition is not trivial and has few rewards within the current academic structure. As a result, researchers interested in the intersection of computational text analysis and historical sources have tended to pursue one of two tracks: experiment with high quality data sets, such as in the cases of Martha Ballards Diary or the Mining the Richmond Dispatch, or to pursue modes of analysis considered more resilient to data errors, such as the text reuse work of Viral Texts and America’s Public Bible.29
Such work has opened the conversation about the use of computational techniques in historical research and provides the necessary first steps in the effort to bring these two methodological approaches together. However, in order for computational methods for history to continue to mature as a form of analysis, the limitations of the available data needs to become a research question to be addressed head-on. With a clear understanding of the data and the types of analysis it reliably supports, the academic community can begin to improve the available data and develop algorithms designed to support the complex, interpretive forms of analysis of the humanities.
Creating Models of Religious Language
Computational text analysis spans a wide range of different strategies for working with textual data, such as computing word frequencies and the correlation between words, identifying and extracting key features such as person and place names, predicting sentiment, identifying text reuse, categorizing texts, and clustering textual features. These techniques can be used as a way to develop data for use as evidence within a larger algorithm or as the core for arguments about the relationship between different aspects of a text or among different factors across an entire corpus. Increasingly of interest in the computational social sciences, textual analysis is used in fields from political science to history to explore legal, political, and cultural language over time as a window onto questions of social and cultural change.30
In a 2014 talk about machine learning and the social sciences, Hanna Wallach described three major categories of modeling tasks: “prediction” of new or missing information based on what is known, which is often the primary concern of computer scientists; “explanation” of the observed patterns, which is the concern of social scientists; and “exploration” of unknown patterns in observed data, which is done by both, and I would add is one of the primary areas of interest for computational humanities scholars.31 While some scholars within literary studies have embraced statistical models to explain patterns in textual data, most work to date in history using computational text analysis has been exploratory or as a mechanism to generate data for other uses.32 One advantage of the exploratory approach is that it fits well within existing disciplinary practices of humanities research, functioning as a way to generate insights into larger data sets or to extract names and places for further analysis. This information can be used to frame research questions or as supporting evidence for a larger interpretive claim.
As part of exploratory analysis, computational methods have been used in history in a range of projects, from those highlighting networks of feminist authors to surfacing patterns in criminal court proceedings.33 Such projects use a range of computational techniques in order to surface, describe, and present aspects of the communities or events of the past, rather than to model or statistically correlate features. Using data analysis to develop an understanding of a larger whole, such projects bridge traditional methods for humanities research and scholarship with the affordances of digital data and computational algorithms. In so doing, they also start the process of identifying the key features within that historical data for further analysis, as well as surfacing the limitation of the data within the much larger context of historical research.
This project continues in the tradition of exploratory data analysis for historical research, in that rather than looking for clear associations between data points, my interest is in generating data that suggests areas for further historical analysis into the development of Seventh-day Adventism. This includes developing a broad view of overall patterns in the language of the denomination, as I demonstrate in Chapter 3, as well as using those patterns to explore the relationship between gender and the perceived nearness of the second coming in their cultural development, seen in Chapter 4. The bringing together of computational and historical methodologies is still rare in historical and digital humanities scholarship, and those projects that utilize both often obscure the contributions of the computational methods, for reasons ranging from institutional norms to constraints of the current publishing model. However, there are productive models for this joining of computational and theoretical approaches.34
To find patterns within my corpus, I used topic modeling, an algorithmic technique that groups words into an arbitrary number of “topics” based on the probability of their co-occurrence within documents. This method is an example of an “unsupervised”algorithm, as I passed all the documents to the algorithm with no contextual or category information other than the number of topics to divide the words into and some additional parameters controlling the way the algorithm processes the data. The main alternative to unsupervised is supervised learning, where a researcher identifies pages as containing, say, “domestic” content, “health”content, or “theological” content, uses an algorithm to identify the features that distinguished those categories from one another, and then uses that model to predict the category of future materials. While supervised algorithms are often more reliable modes of computational text analysis, they require the use of a “labeled” dataset, where the documents have already been assigned to different categories, often by content experts. With the scale of the periodical literature of the denomination and the constraints of the single-author dissertation, this type of analysis is a future goal for the project, but not one that could reasonably form the basis of the dissertation research. Unsupervised learning, by contrast, does not require such up front categorization work on the part of the researcher, and provides a way to view broad patterns across large bodies of texts, patterns which could be used in subsequent research to create labeled data.
Topic models generate a high-level overview of a body of literature, using patterns in word frequency and co-occurrence to identify different topics or subjects of discourse. Developed initially to address the problem of identifying relevant content within the exponentially growing universe of scientific literature, topic modeling algorithms are optimized for problems of information retrieval and summary. Although they work best with the more regular and topically focused content of academic journals, they have been used to explore the content of a range of textual artifacts, including novels, poetry, newspapers, and diaries.35 As researchers have experimented with topic models for modeling relationships between textual features and variables such as the gender of an author, the time of publication, and other metadata aspects, new and more complex versions of the algorithm have been released. These libraries, such as Structural Topic Model (STM) and Dynamic Topic Model (DTM), factor in these different relationships as part of the model, and provide tools for computing the effect of the different variables on the topic distribution.36 This enables a statistical calculation of the effect of different variables on structure of the model, such as the effect of news sources on the frequency and type of coverage for a topic.37
My choice of topic modeling as my primary exploratory method was informed by the research questions I was pursuing and the quality of the data available. While there are many forms of computational text analysis that the periodical data of the SDA might support, not all of those methods were clearly appropriate either to the questions at hand or to the still messy data extracted from the scanned periodicals. Examining the role of time in the development of the culture of Seventh-day Adventism is a question that requires the exploration of language use as well as development of “latent” or implicit patterns in discourse over time. This work lends itself to an exploratory approach, where computational methods are used to surface broad patterns in the textual data and to identify places for further close reading. While topic modeling has its disadvantages, in that as a probabilistic model it is not repeatable in ways required by more explanatory research and its “accuracy” is difficult to evaluate, it offers a useful mechanism for quickly summarizing and clustering large bodies of text in ways that can be used to guide further research and analysis.38
I used the more basic topic modeling algorithm of MALLET to reduce the complexity of the algorithmic assumptions at play in tracking the discourse of the denomination over time.39 Modeling the relationship between discourse and time is not straightforward and the type of change over time assumed in more complex topic modeling algorithms is one of gradual and continuous change. Such models do not account well for moments of historic rupture or for communities where a cyclical pattern is operative.40 For early Seventh-day Adventists, time was not a static category of experience — time and the experience of temporality were part of what denominational members contested and were striving to understand. While more complex topic modeling algorithms can provide additional nuance in classifying large collections of documents and in measuring the statistical strength of relationships between different aspects of texts, such as date and word usage, these algorithms simultaneously impose external assumptions about textual change over time, making the results more difficult to interpret as a part of historical analysis.
Choice of Preprocessing Techniques
Using computational methods in historical research involves not only the application of computational algorithms to the materials and questions of the past, but is shaped by the processing steps both before and after the creation of the computational model. While this work is often ignored or only obliquely referenced as part of the processes that led to the more interesting final model, as Rhody and Burton have argued the work of text preparation and post analysis greatly shapes the resultant model and the shape of developing analysis.41 Particularly as one moves toward analysis based on computational analysis, details such as tokenization, stopwords, and phrase-handling require clarification as through them one encodes assumptions about how the language is functioning rhetorically for a community and how that should be modeled. In this section and the one to follow, I provide a descriptive outline of the steps I took to prepare the textual data for analysis with the topic modeling algorithm. For this project, I chose three preprocessing strategies to streamline the data for analysis and improve the quality of the resulting model: joining of noun phrases, using a customized stopword list, and filtering the documents for training the model on length and accuracy.
Determining where words begin and end is a significant first step in preparing a text for computational analysis. By default, MALLET parses each word of a text as as separate entity, on the assumption that each individual word carries a unique semantic value. While a useful rubric, however, this approach has its limitations. The most apparent limitation is the disconnect between the use of individual words and the common use of “noun phrases” to refer to particular people or concepts. For example, the concept of “old” is included in but is different from the concept of “old age,” a separate referent used to discuss the condition of those in the final years of life. One advantage of attending to phrases is that it helps provide additional specificity to a model. Because it groups together words that tend to co-occur in documents, topic modeling will often generate topics where repeated pairs, such as “old” and “age,” occur as part of the same topic. However, it is difficult in such topics to know whether “old age” as a particular concept is being deployed, or if the author is speaking more generally about the past. By identifying and grouping together noun phrases, it is possible to introduce additional data points into the equation, so that in the text the concepts of “old” and “age” coexist with a concept of “old age” that is built from but is distinct from those component parts.42
In order to identify and work with the noun phrases within the periodical literature, I used the Python library TextBlob to identify noun phrases within the corpus and calculate their frequencies. I saved the two thousand most common phrases to a list, which I used while preparing the texts for MALLET. For each document to be fed to the model, I used TextBlob to identify the noun phrases in the document, and for those phrases that also were in the top two thousand list, I joined the words with an “_”, thereby creating a single combined token for each of these high frequency noun phrases. The result, which you can see in the topic model browser, is that some of the common names and phrases of the denominational literature, such as “jesus christ” and “sabbath school” are processed in the model as single entities.43
My second intervention into the preprocessing of the textual data was in the creation of a subject-specific stopword list for the Seventh-day Adventist periodical literature. Rather than use an existing list, which is the default MALLET process for removing high-frequency but low-meaning words, I used another topic modeling library, Gensim, to identify those words that occurred in more than sixty percent of documents (high frequency words) and those that occurred in fewer than twenty total documents (low frequency words) and used that list as my stopwords list. This approach had two advantages for the particularities of this corpus. First, the language of the denominational periodicals is unusual by twentieth century standards, and very repetitive. While standard wordlists focus on removing common function words (“the”, “and”, etc.), noise for this corpus included what would otherwise be considered meaningful nouns, such as “god.” Scholars such as Rhody have raised concerns regarding the practice of relying on standard stopword lists when processing texts for humanities research.44 This approach provides an alternative to relying on standard lists or manually curating a subject-specific list, building on the particularity of a given text and using that to automate the identification of words to remove. Secondly, while I took a good deal of care in the identification and removal of OCR errors, the methods I pursued are far from comprehensive, resulting in a high number of remaining errors that were generated through failed character recognition. Rather than attempting to identify all of the permutations of errors in recognition, I set the cut off at fewer than twenty documents as a way of identifying those words that are too unique to be useful at the abstract level of a model, including the generated OCR errors. By providing a mechanism to address both high frequency words and errors that appear in few documents, the Gensim library provided a way to reduce the words for analysis while following the contours of the historical text. Through this process, I generated a stopword list particular to the specialized language of the SDA and the eccentricities of my data.
In these first two preprocessing steps, I considered what a “word” was within the context of the Seventh-day Adventist literature and which of those words were most likely to carry the distinctive meaning within the body of the text. My final preprocessing step was to narrow the corpus for model creation to those documents with sufficient words and low error rates. As a form of probabilistic textual analysis, topic modeling is sensitive to OCR errors, particularly errors that inflate the number of words in the documents, as they skew the “weights” assigned to the words.45 To counter-balance this problem, particularly as the documents in my study while clean were not error free, I limited my training set to documents with more than three hundred words and error rates under ten percent. Once I had generated the model, I went through and classified these “hold-out” documents, so that they too were visible to my analysis, but the model itself is only based on those high quality documents.
This process of moving from text to data is one that can be done in multiple ways depending on research questions, features of the text, and the like. All of these decisions effect the patterns that can be seen in standard machine learning algorithms, and yet rarely are these steps carefully documented in research in the digital humanities.46 However, for these methods to continue to develop within the humanities, they must be documented, examined, and engaged. Preprocessing methods such as these change the shape of the final models and the research cannot be reproduced without including these seemingly mundane steps to shape the data into its form for analysis. My inclusion of this discussion, together with code examples, is part of an explicit and implicit argument that this intellectual work is as much part of the A Gospel of Health and Salvation as the prose and visualizations to follow.
Evaluating and Analyzing the Topic Model
Of the methods for statistical analysis of a corpus, topic modeling presents some unique challenges in that the algorithm is probabilistic, not deterministic. If you were to run a model on the same corpus multiple times, the results will vary in the words that constitute a topic and the weights assigned to topics within documents. And as the method is unsupervised, there is no “ground truth” against which to evaluate the results. These aspects of topic models have led many researchers to be justifiably cautious about the usefulness of the method for generating historical and interpretive insights. Additionally, the human tendency to find patterns, to “read tea leaves,” means that topic models are highly susceptible to seeming more coherent than they in fact are.47 These drawbacks are particularly significant when topic models are used as data for calculating the relationship between variables. As a form of exploratory data analysis, topic modeling provides different “readings” of the patterns of word usage. While holding too closely to the results will lead to error, these readings are helpful in identifying general themes and overall patterns.
This is not to say that there are no mechanisms for evaluating the quality and stability of a given topic model. In fact, there are a growing range of strategies used to evaluate and improve the quality of topic models as scholars have worked to find ways to make the results of the model more stable and coherent.48 These strategies provide useful mechanisms for examining the internal structure of a model and increasing confidence that said model provides a useful abstraction of the underlying literature. For the dissertation, I pursued three general strategies for evaluating the quality and stability of the topic model. These were to visualize the relationship between topics within the model, to measure the overlap between topics when the model was run on different permutations of the corpus, and to evaluate the legibility of the topics, or the ease with which they could be labeled, and the match between the topic and the originating content. Together these methods provide a picture of a model with some redundancy in topics but with enough distinction to enable focusing in on the shifting focus of the denomination’s rhetoric over time.
Visual representations of topic models provide a useful initial mode of entry into understanding how the words within the denominational literature have been grouped in relation to each other. For the dissertation, I used the PyLDAviz library to graph the dissertation topics in two dimensional space using principle component analysis, as well as the Plot.ly graphing library to create a dendrogram of the topics, defined in terms of a vector of their top fifty words.49 Each of these visualizations is focused on the relationship between the topic as defined by the words that compose them, rather than by their prevalence in the documents of the corpus.
The visualization generated with PyLDAviz depicts a model with no clear predominant topic, and a number of topical clusters. For example, the top center of the graph shows a closely grouped cluster of topics related to issues of food and diet, derived from the health reform literature of the denomination. The bottom left corner of the graph shows a clustering of topics around issues of faith, including theology and biblical quotations. The bottom right corner, in contrast, clusters topics around more bureaucratic aspects of the denomination, including conference reports and missions. Finally, at the near center of the graph is the (here labeled) topic 22 which includes “study,” “instruction,” “plan.” The position of this cluster of verbs at the center of the graph suggests that these words appear across all of the different discursive areas of the denominational literature. As a people of the book, deeply committed to studying the divine law in both scripture and in nature, the centrality of that concept to all of their discourse would be appropriate.
A dendrogram provides another window onto the relationships between the topics of the model. Created using the default options within the Plotly library, this chart uses the top 50 words in each topic to cluster and computes the distances between the different topic pairs. The resulting chart again indicates a high degree of similarity between the topics with some definite clusters of related topics. At the bottom of the chart the reader can find a small collection of education-focused topics, while topic 20, related to church organization, is displayed at the top of the graph, with language distinctive from that of all the other topics. Within the large block of maroon topics, clear clusters relating to conference reports, to church and state legislation, and to theological topics such as the sabbath appear. While the PyLDAviz graph relies only on the topic words, in addition to showing relationships between topics, I incorporated topic labels into the dendrogram graph, and used it as a partial guide for the work of labeling topics and identifying related topics for further study.
The second strategy I pursued to evaluate the model generated through MALLET was to measure the stability of the topical word clusterings over different permutations of the corpus. For this, I used the topic keys, which consists of the top twenty words for each topic, from four topic models created from four different variations on the corpus: a random selection of documents within the corpus, a corpus where the minimum error rate was computed at twenty-five percent, a corpus where no minimum error rate was set, and the target configuration with an error rate set at ten percent. Using Levenshtein distance to compute the similarity between the words in the topic keys, I computed the distances between all of the words in each topic key pair, used the lowest distances to indicate the most similar words, and computed the percentage of tokens with a match within a low number of edits.50 In the random and twenty-five percent error rate case, ninety-six percent of the topics had a close match, while ninety-four percent of topics in the sample with no controls on error rates had a close match. This result indicated to me that although there is some shifting in the relative weights of words across the different runs of the topic model, overall, there was a close match for each of the main topics. Additionally, the lower return from the model with no constraints on the error rates suggests that the effort to control for those documents did make a measurable difference in the shape of the topics. While additional work should be done around the evaluation and optimization of topic models for use in historical analysis, these rough measures provide an initial measure of confidence regarding the stability and usefulness of the topic model.51
My final strategy for evaluating the topic was interpretive, drawing upon my position as a subject expert to evaluate the coherence and usefulness of the model. To do this, I looked both directly at the topics, particularly the internal coherence of the topic words and the overlap between topics, as well as the connections between topics and the documents where the topics featured predominantly. Reading the topics at these three scales, I assigned interpretive labels to the topics. These labels serve to indicate the content that is represented within the model by the topic and are used to track the prevalence of different topics over time. While many of the topics were composed of words with clear subject matter focuses, a number of topics captured particular modes of communication, rather than particular content. For example, one topic that was prevalent in the early years of the denominational publications, topic 56, falls into this particular category. Although the underlying tie between the topic words is not immediately apparent — “lord truth bro sister feel jesus” — an examination of the pages where this topic is prevalent quickly indicates that this topic has captured the confessional language used by those who wrote to James and Ellen White in the early days of Seventh-day Adventism. Of the strategies for evaluating the model, this interpretive work was the most time consuming, as it required bringing together the different distances of the model and the text to develop an understanding of the language pattern that was captured. However, it is also this step that most firmly embeds my particular use of the topic model within the realm of historical interpretation. I return to my process of labeling the topics in Chapter 3.
By combining these three strategies, I evaluated the model with reference to visual, mathematical, and interpretive frameworks and came to two-hundred and fifty as a workable number of topics for the final model. This scale of topic model enabled me to capture some of the more nuanced aspects of the periodical literature, while also limiting the fracturing of themes between multiple topics. The larger number of topics also provides space for topics to shift, with similar topics capturing different topical associations as the literature of the denomination developed over time. By carefully attending to the relationship between the words, topics, and documents, I have developed a clearer understanding of the contours of the literature the model describes as well as a degree of confidence in the usefulness of the model for describing the overall corpus as well as for directing the reader back to the particular texts. Those two roles of description and guidance are what I require from the topic model for this historical study.
Presenting the Topic Model
Generating a topic model is the first part of the challenge; using and interpreting a topic model within historical analysis is a second and less discussed project. For classification problems, where a researcher uses the model to generate and assign topical categories to different documents, outputs such as the breakdown of topic percentages for each document allow the researcher to identify the most prevalent topics in each document, and use the associated label as a descriptive tag or category. Topic models also provide an overview of topic distributions across the entire set of documents, providing a snapshot of the major and minor themes in a corpus. As a form of machine learning, topic models can be used to classify new content, enabling researchers to use a previously generated model to classify previously unseen content.
Researchers in the digital humanities have pursued several different strategies to bridge the computational and abstract data of topic models with the interpretive questions of the humanities. My goal in working with a topic model is not to argue for correlations between different facets of SDA discourse, but to surface broad patterns and identify areas for further research. This use of a computational model fits within the epistemological commitments of the humanities, with its emphasis on complexity, multiple causality, and the idiographic, rather than using the model to argue for correlations between discourse patterns and metadata variables. My primary areas of interest are within the humanities: to find ways to explore particular aspects of religious culture, to understand how a belief system functions and changes, and to consider how those patterns of thought have been built upon to shape the current cultural landscape. These are questions that I believe computational models and methods can help in the exploration of, but as one method among others, including traditional archival research and narrative construction.
Topic models provide vast amounts of information describing their respective corpora, information that can be used to identify patterns across the documents as well as to identify content on particular themes. One advantage of working in a digital medium is that it is possible to provide an interactive interface for the model, one that allows the researcher to highlight particular aspects of the model or the corpus, but that also opens the possibility for readers to use the model to further explore those or other themes. For A Gospel of Health and Salvation I used a topic model browser as part of the dissertation to enable topic exploration. This platform, while sufficient for the research of the dissertation, also serves as a “rough draft” for a future interface for the periodical literature of the denomination, one that supports the integration of the research and scholarly presentation.
The topic model browser I am using for the dissertation, hosted at http://browser.dissertation.jeriwieringa.com/, is an adaptation of Andrew Goldstone’s DfR browser. The browser is built using the D3 Javascript library and works from model data generated using the MALLET library.52 The browser provides the reader with interfaces that highlight the topical trends over time, the document composition, and the relationships between words and between words and topics. These different views enable the reader to explore when a topic was predominant in the corpus, examine the other topics associated with the documents where the topic is prevalent, and inspect the words that compose the topic, to see in which other topics those words are prevalent. To compute topics over time, the data processing function aggregates the topic assignments by year, smooths those values by the “alpha” hyperparameter used in MALLET and displays the percentage of tokens that constitutes each topic per year. This method of computing topics over time is one that I continue within the other interfaces of the dissertation. I discuss the different views of the browser in the browser about page.
In using this interface, I present the topic model as an abstraction of and a guide to the broad periodical literature of the denomination. Even with this degree of abstraction, there is more information in these interfaces than can be accounted for in a singular narrative and so while the interfaces enable my exploration of end-times and the cultural development of the denomination, by exposing the larger model, I invite the reader to explore whether those patterns do indeed hold within the larger, undiscussed context of the literature. I do not claim, however, that this model or these interfaces provides a neutral entry point into the denominations literature. Rather, as discussed throughout the chapter, all of the aspects that make up the model — the selection of sources, the data preparation steps, the choice and optimization of the algorithm, and the design of the interfaces — are oriented toward the interpretive goals of the project. The usefulness of the interfaces, the model, or the data for other projects would be dependent upon whether those choices support the desired analysis. This approach presents an alternative to the model of a neutral data interface that supports multiple research projects.
Conclusion
While all historical research involves the selection of materials, the analysis of those materials, and the organization of that analysis into some form of presentation, the incorporation of computational methods into that process is not a simple addition. Rather, the complexity of the analysis increases exponentially, as the layers of code and algorithms enact and embed interpretive and analytical assumption throughout the seemingly neutral processes of preparing and parsing the data. These processes can be undertaken in multiple ways and their documentation is necessary for that work to be inspected, reproduced, and evaluated. As a result, the computational work involved in digital scholarship expands the prevailing model of scholarship in ways that do not have clear parallels in traditional research practices. From source selection to preprocessing to choice of algorithm and modes of interaction, the technical work of computational analysis is all part of the scholarly work that constitutes a digital humanities project, intertwined with the interpretive questions and constraining the very contours of what can be seen through the resultant model. As a result, that work is properly part of the scholarly output of computational research in history.
For example, see Matt Burton, “Blogs as Infrastructure for Scholarly Communication.” (PhD thesis, University of Michigan, 2015); Nan Z. Da, “The Computational Case Against Computational Literary Studies,” Critical Inquiry 45, no. 3 (2019): 601–39, https://www.journals.uchicago.edu/doi/10.1086/702594.↩
Historian Catherine Brekus notes that while “earlier evangelicals had realized the potential of the press, the Millerites published tracts, memoirs, and newspapers on a scale never before imagined.” Catherine A. Brekus, Strangers and Pilgrims: Female Preaching in America, 1740-1845 (Gender and American Culture), 1st New edition (Chapel Hill: The University of North Carolina Press, 1998), p. 323.↩
James White, “Dear Brethren and Sisters —,” The Present Truth 1, no. 1 (1849): 6, http://documents.adventistarchives.org/Periodicals/PT-AR/PT-AR-Part1-01.pdf, p. 6.↩
Ellen Gould Harmon White, “Dear Brethren and Sisters —,” The Present Truth 1, no. 11 (1850): 86–87, http://documents.adventistarchives.org/Periodicals/PT-AR/PT-AR-Part1-11.pdf, pp. 86-87. In subsequent tellings of this history, a more direct link is told between Ellen’s vision and the start of The Present Truth. See Floyd Greenleaf and Jerry Moon, “Builder,” in Ellen Harmon White: American Prophet, ed. Terrie Dopp Aamodt, Gary Land, and Ronald L. Numbers (New York: Oxford University Press, 2014), pp. 126-7 & 140 n.2 and n.6.↩
Benedict Anderson, Imagined Communities: Reflections on the Origin and Spread of Nationalism, Revised Edition (London; New York: Verso, 2006), p. 6.↩
Information about the history of the denominations periodical digitization efforts from an email exchange with the archivist for the Adventist Digital Library. Eric Koester, “Inquiry Regarding Data from the Adventist Digital Library.” Email, 2017, Eric Koester and Henry Gomes, eds., “About,” Adventist Digital Library, 2017, http://adventistdigitallibrary.org/about.↩
For reference see the Series 4 and 5 lists of the titles included in the AAS’s collection at https://www.ebscohost.com/archives/aas-historical-periodicals-collection. The dates for the issues of the Youth’s Instructor suggests that even for titles where the denomination’s coverage has gaps, their collection is more extensive than what is available through the AAS database.↩
“Religious liberty” for Seventh-day Adventist writers refers primarily to resisting the passage of Sunday observance laws. While anticipating future cooperation between the Catholic church and the United States government on Sunday observance in the events leading up to the second coming, they also worked to raise awareness about these pieces of legislation and sought to use the first amendment to defend themselves against the passage of these laws.↩
The Seventh-Day Adventist Year Book, 1883 (Battle Creek, MI: Seventh-day Adventist Publishing Association, 1883), http://documents.adventistarchives.org/Yearbooks/YB1883.pdf, pp. 55, 57.↩
1905 Year Book of the Seventh-Day Adventist Denomination (Washington, D.C.: Review; Herald Publishing Association, 1905), http://documents.adventistarchives.org/Yearbooks/YB1905.pdf, pp. 100-105; H. Edson Rogers, ed., Year Book of the Seventh-Day Adventist Denomination (Takoma Park, Washington, D.C.: Review & Herald Publishing Association, 1921), pp. 183-186.↩
See Table 2.1 for a full listing of the periodicals I identified and their digitization status.↩
See https://en.wikipedia.org/wiki/Garbage_in,_garbage_out↩
For example, see John Evershed and Kent Fitch, Correcting Noisy Ocr: Context Beats Confusion (New York: ACM Press, 2014), Thomas A. Lasko and Susan E. Hauser, Approximate String Matching Algorithms for Limited-Vocabulary Ocr Output Correction, 2000, and Ted Underwood, “The Challenges of Digital Work on Early-19c Collections.” The Stone and the Shell, 2011, https://tedunderwood.com/2011/10/07/the-challenges-of-digital-work-on-early-19c-collections/.↩
Roy Rosenzweig, “Scarcity or Abundance? Preserving the Past in a Digital Era,” The American Historical Review 108, no. 3 (2003): 735–62, http://www.jstor.org/stable/10.1086/529596, 739.↩
Patrick Spedding assesses ECCO for the document base, the search interface, and the accuracy of the textual layer in Patrick Spedding, “‘The New Machine’: Discovering the Limits of Ecco,” Eighteenth-Century Studies 44, no. 4 (2011): 437–53, http://www.jstor.org/stable/41301590, while Tim Hitchcock evaluates the Burney Collection for word accuracy in Tim Hitchcock, “Confronting the Digital: Or How Academic History Writing Lost the Plot,” Cultural and Social History 10, no. 1 (2015): 9–23, http://www.tandfonline.com/doi/full/10.2752/147800413X13515292098070. In both studies, the authors raise significant concern about the quality of the data upon with the search and recovery interfaces are built, as well as the lack of transparency on the part of the database providers, in both cases Gale, regarding the underlying data.↩
Andrew J. Torget et al., “Mapping Texts: Combining Text-Mining and Geo-Visualization to Unlock the Research Potential of Historical Newspapers,” Mapping Texts, 2011, http://mappingtexts.org/whitepaper/MappingTexts_WhitePaper.pdf, 7↩
For the project, “good” and “bad” words are determined by comparison to dictionary of words.↩
For examples, see Evershed and Fitch, Correcting Noisy Ocr; Lasko and Hauser, Approximate String Matching Algorithms for Limited-Vocabulary Ocr Output Correction; Thomas L. Packer, “Performing Information Extraction to Improve Ocr Error Detection in Semi-Structured Historical Documents,” Proceedings of the 2011 Workshop on Historical Document Imaging and Processing, 2011, 67, https://dl.acm.org/citation.cfm?id=2037354; Carolyn Strange et al., “Mining for the Meanings of a Murder: The Impact of Ocr Quality on the Use of Digitized Historical Newspapers,” Digital Humanities Quarterly 8, no. 1 (2014), http://www.digitalhumanities.org/dhq/vol/8/1/000168/000168.html; Torget et al., “Mapping Texts.”; Underwood, “The Challenges of Digital Work on Early-19c Collections.”; Ted Underwood and Loretta Auvil, “Basic Ocr Correction,” The Uses of Scale in Literary Study, 2014, https://usesofscale.com/gritty-details/basic-ocr-correction/.↩
Evershed and Fitch, Correcting Noisy Ocr, 45.↩
Simon Tanner, Trevor Muñoz, and Pich Hemy Ros, “Measuring Mass Text Digitization Quality and Usefulness: Lessons Learned from Assessing the Ocr Accuracy of the British Library’s 19th Century Online Newspaper Archive,” D-Lib Magazine 15, no. 7/8 (2009), http://dx.doi.org/10.1045/july2009-munoz, §5.↩
Lasko and Hauser, Approximate String Matching Algorithms for Limited-Vocabulary Ocr Output Correction; Underwood2011.↩
Kevin Atkinson, “Spell Checking Oriented Word Lists (Scowl),” 2016, http://wordlist.aspell.net/scowl-readme/↩
Nathan O Hatch, The Democratization of American Christianity (New Haven: Yale University Press, 1989), 5.↩
More recent versions of OCR software have become better at dealing with the vagaries of older print documents. However, much of the currently circulated PDF scans and textual data were created with earlier iterations of the software. Another solution, one that is often featured in larger subscription collections, is to devote the time and energy to identify and catalog each individual article within the digitized document. This approach often introduces other complications around the more marginal aspects of older documents, including advertisements, which are often less differentiated than the main content.↩
http://documents.adventistarchives.org/Periodicals/HR/HR18660801-V01-01.pdf#page=3↩
All of these steps are outlined in a Jupyter notebook for readers interested in the technical details.↩
This includes word embeddings, neural networks, and key words in context(KWIC). Benjamin M. Schmidt, “Word Embeddings for the Digital Humanities,” 2015, http://bookworm.benschmidt.org/posts/2015-10-25-Word-Embeddings.html; Akemi Ueda, “Stanford Literary Lab Uses Digital Humanities to Study Why We Feel Suspense,” 2016, https://news.stanford.edu/2016/02/18/literary-lab-suspense-021816/.↩
Benjamin M. Schmidt, “Interactive Visual Bibliography: Describing Corpora,” 2018, http://creatingdata.us/techne/bibliographies/; Yonghui Wu et al., “Google’s Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation,” CoRR abs/1609.08144 (2016), http://arxiv.org/abs/1609.08144.↩
The problem of OCR is the focus of a recent report from Northeastern University, funded by the Mellon Foundation. While a little discussed problem when I began this dissertation, the problem of data quality from scans of historical documents is becoming increasingly recognized in the field. David A. Smith and Ryan Cordell, “A Research Agenda for Historical and Multilingual Optical Character Recognition,” 2018, https://ocr.northeastern.edu/report/.↩
For a list of projects using computational text analysis in various fields, see Brendan O’Connor, David Bamman, and Noah A. Smith, “Computational Text Analysis for Social Science: Model Assumptions and Complexity,” Second NIPS Workshop on Computational Social Science and the Wisdom of Crowds, 2011, https://homes.cs.washington.edu/~nasmith/papers/oconnor+bamman+smith.nips-ws11.pdf, pp. 1-2.↩
Hanna Wallach, “Big Data, Machine Learning, and the Social Sciences: Fairness, Accountability, and Transparency,” 2014, https://medium.com/@hannawallach/big-data-machine-learning-and-the-social-sciences-927a8e20460d↩
Examples include the work of Matthew Jocker, Ted Underwood, and Andrew Piper. Gabi Kirilloff et al., “From a Distance ‘You Might Mistake Her for a Man’: A Closer Reading of Gender and Character Action in Jane Eyre, the Law and the Lady, and a Brilliant Woman,” Digital Scholarship in the Humanities 33, no. 4 (2018), https://academic.oup.com/dsh/article-abstract/33/4/821/5004302?redirectedFrom=fulltext; David Bamman, Ted Underwood, and Noah A. Smith, “A Bayesian Mixed Effects Model of Literary Character,” Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014, 370–79; Andrew Piper, Enumerations: Data and Literary Study (Chicago: University of Chicago Press, 2018).↩
For example, historian Michelle Moravec addresses the limitations of network analysis for historical scholarship in Michelle Moravec, “Network Analysis and Feminist Artists,” Artl@s Bulletin 6, no. 3 (2017): Article 5, https://docs.lib.purdue.edu/cgi/viewcontent.cgi?referer=\&httpsredir=1\&article=1124\&context=artlas.↩
For example, in his dissertation on the Digital Humanities community, Matt Burton uses topic modeling along with digital ethnography to explore the character and development of digital humanities blogs. Burton, “Blogs as Infrastructure for Scholarly Communication.”↩
Some high-profile projects in the digital humanities that use topic modeling on a range of different types of content include Ted Underwood and Andrew Goldstone’s exploration of the archives of the PMLA journal, Lisa Rhody’s study of ekphrasis poetry, Robert Nelson’s work with the Richmond Daily Dispatch, Sharon Block’s work with the Pennsylvania Gazette, Cameron Blevins’s explorations of Martha Ballard’s diary, and Micki Kaufman’s exploration of the Kissinger Collection. Andrew Goldstone and Ted Underwood, “What Can Topic Models of Pmla Teach Us About the History of Literary Scholarship?” Journal of Digital Humanities 2, no. 1 (2013), http://journalofdigitalhumanities.org/2-1/what-can-topic-models-of-pmla-teach-us-by-ted-underwood-and-andrew-goldstone/; Lisa M. Rhody, “Topic Modeling and Figurative Language,” Journal of Digital Humanities 2, no. 1 (2013), http://journalofdigitalhumanities.org/2-1/topic-modeling-and-figurative-language-by-lisa-m-rhody/; Robert K. Nelson, “Mining the Dispatch,” 2007, http://dsl.richmond.edu/dispatch/pages/home; Sharon Block, “Doing More with Digitization,” Common-Place the Interactive Journal of Early American Life 6, no. 2 (2006), http://www.common-place-archives.org/vol-06/no-02/tales/; Cameron Blevins, “Topic Modeling Martha Ballard’s Diary,” 2010, http://www.cameronblevins.org/posts/topic-modeling-martha-ballards-diary/, Micki Kaufman, “‘Everything on Paper Will Be Used Against Me’: Quantifying Kissinger. A Computational Analysis of the National Security Archive’s Kissinger Collection Memcons and Telcons,” 2018, http://blog.quantifyingkissinger.com/.↩
Molly Roberts et al., “The Structural Topic Model and Applied Social Science,” NIPS 2013 Workshop on Topic Models: Computation, Application, and Evaluation, 2013, https://scholar.princeton.edu/files/bstewart/files/stmnips2013.pdf; David M. Blei and John D. Lafferty, “Dynamic Topic Models,” Proceedings of the 23rd International Conference on Machine Learning, 2006, 113–20, https://doi.org/10.1145/1143844.1143859↩
For an example of this type of research, see Margaret E. Roberts, Brandon M. Stewart, and Edoardo M. Airoldi, “A Model of Text for Experimentation in the Social Sciences,” Journal of the American Statistical Association 111, no. 515 (2016): 988–1003, https://www.tandfonline.com/doi/full/10.1080/01621459.2016.1141684.↩
Jonathan Chang et al., Reading Tea Leaves: How Humans Interpret Topic Models, vol. 22 (Neural Information Processing Systems Foundation, Inc., 2009). One additional advantage of using topic modeling as part of an exploratory approach to the data from the SDA periodicals is the flexibility the algorithm provides for dealing with the messy textual data of the denomination. While studies have shown that algorithms that use weights in evaluating textual data, such as computing the relative uniqueness of given terms in each document, are particularly sensitive to errors in the data, particularly those introduced by OCR, there are clear strategies for mitigating the effects of such errors. For example, one can separate the work of model creation from the categorization of all documents, where the model is trained on one set of documents, but applied to the full collection. By limiting the training set to documents with low error rates and higher word counts, one can improve the quality of the resulting model by excluding some of the “noise” introduced by error-filled documents. Gudila Paul Moshi et al., “An Impact of Linguistic Features on Automated Classification of Ocr Texts,” Proceedings of the 9th IAPR International Workshop on Document Analysis Systems, 2010, 287–92, https://dl.acm.org/citation.cfm?doid=1815330.1815367; Daniel Walker, William Lund, and Eric Ringger, “Evaluating Models of Latent Document Semantics in the Presence of Ocr Errors,” Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, 2010, 240–50, http://hdl.lib.byu.edu/1877/3561.↩
Andrew Kachites McCallum, “MALLET: A Machine Learning for Language Toolkit (2.0.8),” 2002, http://mallet.cs.umass.edu↩
For a detailed discussion of time in topic modeling algorithms, see Benjamin M. Schmidt, “Words Alone: Dismantling Topic Models in the Humanities,” Journal of Digital Humanities, 2013, http://journalofdigitalhumanities.org/2-1/words-alone-by-benjamin-m-schmidt/ internal-pdf://7981/words-alone-by-benjamin-m-schmidt.html↩
Rhody, “Topic Modeling and Figurative Language.” and Burton, “Blogs as Infrastructure for Scholarly Communication.”.↩
This approach is discussed by David Mimno as one strategy for generating more meaningful models. David Mimno, “Using Phrases in Mallet Topic Models,” 2015, http://www.mimno.org/articles/phrases/.↩
This was not a fool proof system, as the phrase “thou_art” illustrates. Here the twentieth-century grammar expectations of the part of speech tagger clashes with the seventeenth-century religious language of the denomination, creating a noun phase out of a common noun-verb pair. Additionally, errors in word order or at times the length of a text caused phrases to be inconsistently recognized by the TextBlob library. However, on the whole, it is a useful strategy for identifying and tagging noun phrases at scale.↩
cite↩
Kazem Taghva, Thomas Nartker, and Julie Borsack, Information Access in the Presence of Ocr Errors, ed. Kirk Lubbes (New York: ACM Press, 2004).↩
Matt Burton makes a similar argument in his work translating Underwood’s “Pace of Change” article into an executable code document. Matt Burton, “Defactoring ‘Pace of Change’,” 2018, https://github.com/interedition/paceofchange/blob/c86e25eb1849d2b02677f82f0198cfd6f567ceb8/defactoring-pace-of-change.ipynb. Reproducible research is a problem outside of the digital humanities as well, as computational methods are increasingly relied upon in the sciences and social sciences. Movements such as Open Science, supported by the Center for Open Science, are working to encourage scientists to make the data and code available as part of standard scientific practice.↩
Chang et al., Reading Tea Leaves.↩
This includes newer varieties of composite models (combining a series of runs into a composite model) and user mediated models, where the user makes corrections on the model. Experimenting with these forms of topic modeling was beyond the scope of what I could accomplish within the dissertation. Mark Belford, Brian Mac Namee, and Derek Greene, “Stability of Topic Modeling via Matrix Factorization,” Expert Systems with Applications: An International Journal 91, no. C (2018): 159–69, https://dl.acm.org/citation.cfm?id=3170753; David Mimno et al., “Optimizing Semantic Coherence in Topic Models,” Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2011, 262–72, https://dl.acm.org/citation.cfm?id=2145462.↩
These representations work by measuring the distance between topics, where each topic is understood as vector of words. Principle component analysis provides a mathematical representation of the most distinguishing features of a dataset. For the topic model, measuring two principle components enables plotting the topics along an x,y axis, where similar topics appear in close proximity within the grid. For an indepth explanation of how the PyLDAviz computes the relationships between the topics, see Carson Sievert and Kenneth E. Shirley, LDAvis: A Method for Visualizing and Interpreting Topics (Baltimore, Maryland: Association for Computational Linguistics, 2014).↩
Levenshtein distance is a measure of the difference between two strings (blocks of text) by comuting the minimum number of edits (additions, subtractions, or substitutions) needed to transform one string into another.↩
Measuring topic stability is a relatively new area of research within topic modeling, and holds promise as a method for both acknowledging and working with the probabilistic shift in topic models over time. For examples see Mika V. Mantyla, Maelick Claes, and Umar Farooq, “Measuring Lda Topic Stability from Clusters of Replicated Runs,” Proceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, 2018, 1–5, https://doi.org/10.1145/3239235.3267435. Further explorations of the stability of the topic model would involve rerunning the model on the same corpus and running an analysis of the resulting topic clusters.↩
The default topic modeler for the browser is the R wrapper for MALLET, but Goldstone also provides a script to transform the data from the command-line MALLET interface for use in the browser.↩